ZFS: Концепции и урок
В търсенето на целостта на данните с помощта на OpenZFS е неизбежно. Всъщност би било доста жалко, ако използвате нещо друго, освен ZFS, за съхранение на вашите ценни данни. Много хора обаче не са склонни да го изпробват. Причината е, че файлова система от корпоративен клас с широк набор от функции, вградени в нея, ZFS трябва да бъде трудна за използване и администриране. Нищо не може да бъде по-далеч от истината. Използването на ZFS е възможно най-лесно. С няколко терминологии и още по-малко команди сте готови да използвате ZFS навсякъде - от предприятието до вашия дом / офис NAS.
По думите на създателите на ZFS: „Искаме да направим добавянето на хранилище към вашата система толкова лесно, колкото добавянето на нови RAM стикове.”
По-късно ще видим как се прави това. Ще използвам FreeBSD 11.1, за да извършите тестовете по-долу, командите и основната архитектура са сходни за всички дистрибуции на Linux, които поддържат OpenZFS.
Целият стек на ZFS може да бъде подреден в следните слоеве:
- Доставчици на хранилище - въртящи се дискове или SSD
- Vdevs - Групиране на доставчиците на хранилище в различни RAID конфигурации
- Zpools - Агрегиране на vdevs в единни пулове за съхранение
- Z-Filesystems - Набори от данни с страхотни функции като компресия и резервация.
Zpool създайте
Като начало нека започнем с настройка къде разполагаме с шест 20GB диска ада [1-6]
$ ls -al / dev / ada?
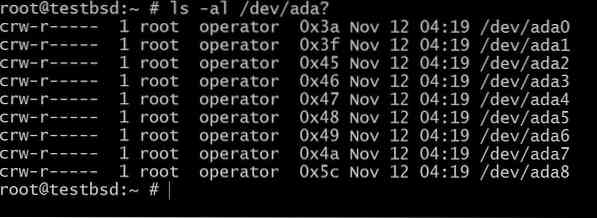
The ada0 е мястото, където е инсталирана операционната система. Останалото ще бъде използвано за тази демонстрация.
Имената на вашите дискове могат да се различават в зависимост от типа на използвания интерфейс. Типичните примери включват: da0, ada0, acd0 и cd. Гледайки вътре/ разработчицище ви даде представа за наличното.
A zpool е създаден от zpool създавам команда:
$ zpool създайте OurFirstZpool ada1 ada2 ada3 # И след това изпълнете следната команда: $ zpool статус
Ще видим изходен изход, който ни дава подробна информация за пула:
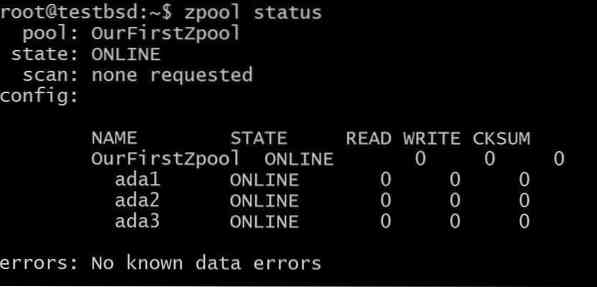
Това е най-простият zpool без излишък или толерантност към грешки ... Всеки диск е свой собствен vdev.
Все пак ще получите цялата доброта на ZFS като контролни суми за всеки блок данни, който се съхранява, за да можете поне да откриете дали данните, които сте съхранили, са повредени.
Файлови системи, a.к.набори от данни, вече могат да бъдат създадени върху този пул по следния начин:
$ zfs създават OurFirstZpool / набор от данни1
Сега използвайте познатото си df -h команда или изпълнение:
$ zfs списък
За да видите свойствата на вашата новосъздадена файлова система:

Забележете, как цялото пространство, предлагано от трите диска (vdevs), е достъпно за файловата система. Това ще важи за всички файлови системи, които създавате в пула, освен ако не посочим друго.
Ако искате да добавите нов диск (vdev), ada4, можете да го направите, като изпълните:
$ zpool добавете OurFirstZpool ada4
Сега, ако видите състоянието на вашата файлова система

Наличният размер вече е нараснал, без да има допълнителна караница за нарастване на дяла или архивиране и възстановяване на данните във файловата система.
Виртуални устройства - Vdevs
Vdevs са градивните елементи на zpool, по-голямата част от резервирането и производителността зависи от начина, по който вашите дискове са групирани в тези, така наречените, vdevs . Нека разгледаме някои от най-важните видове vdevs:
1. RAID 0 или ивици
Всеки диск действа като свой собствен vdev. Няма излишък на данни и данните се разпространяват по всички дискове. Известен още като райе. Неизправността на един диск би означавала, че целият zpool е направен неизползваем. Използваното хранилище е равно на сумата от всички налични устройства за съхранение.
Първият zpool, който създадохме в предишния раздел, е RAID 0 или райест масив за съхранение.
2. RAID 1 или Mirror
Данните се отразяват между ндискове. Действителният капацитет на vdev е ограничен от суровия капацитет на най-малкия диск в него н-дисков масив. Данните се отразяват между н дискове, това означава, че можете да издържите провала на n-1 дискове.
За да създадете огледален масив, използвайте ключовата дума mirror:
$ zpool създайте огледало за резервоар ada1 ada2 ada3
Данните, записани в резервоар zpool ще бъде огледален между тези три диска и действителното налично хранилище е равно на размера на най-малкия диск, който в този случай е около 20 GB.
В бъдеще може да искате да добавите още дискове към този пул и можете да направите две възможни неща. Например zpool резервоар има три диска, отразяващи данни като един vdev mirror-0:
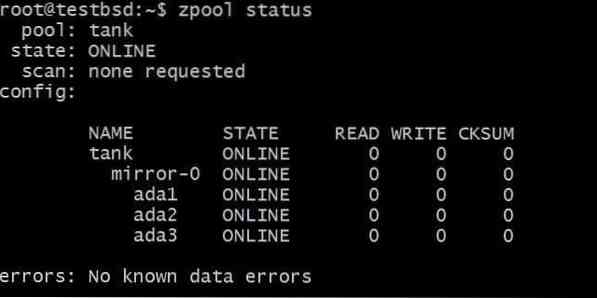
Може да искате да добавите допълнителен диск, да речем ada4, да отразяват същите данни. Това може да стане чрез стартиране на командата:
$ zpool прикрепете резервоар ada1 ada4
Това би добавило допълнителен диск към vdev, който вече има диска ada1 в него, но не и да увеличи наличното хранилище.
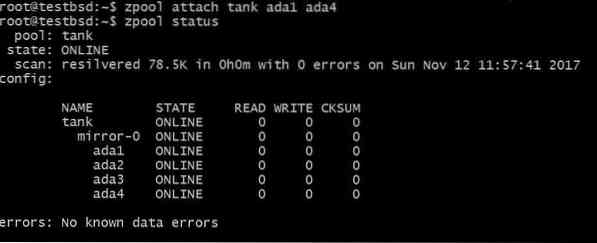
По същия начин можете да отделите устройства от огледало, като изпълните:
$ zpool отделящ резервоар ada4
От друга страна, може да искате да добавите допълнителен vdev, за да увеличите капацитета на zpool. Това може да се направи с помощта на командата zpool add:
$ zpool добавете огледало за резервоар ada4 ada5 ada6
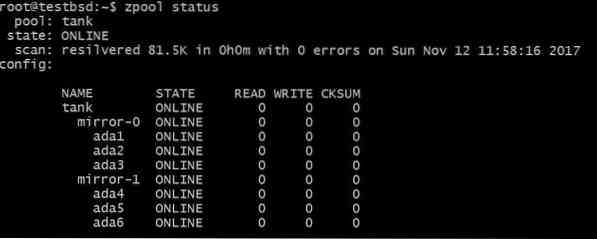
Горната конфигурация ще позволи на данните да бъдат очертани върху vdevs mirror-0 и mirror-1. В този случай можете да загубите 2 диска на vdev и данните ви ще останат непокътнати. Общото полезно пространство се увеличава до 40GB.
3. RAID-Z1, RAID-Z2 и RAID-Z3
Ако vdev е от тип RAID-Z1, той трябва да използва поне 3 диска и vdev може да понесе смъртта само на един от тези дискове. Конфигурациите RAID-Z не позволяват прикачване на дискове директно към vdev. Но можете да добавите още vdevs, като използвате zpool добавяне, такива, че капацитетът на басейна може да продължи да се увеличава.
RAID-Z2 ще изисква поне 4 диска на vdev и може да толерира до 2 дискови отказа и ако третият диск се провали преди да бъдат заменени 2 диска, вашите ценни данни се губят. Същото следва и за RAID-Z3, който изисква най-малко 5 диска на vdev, с до 3 диска на толерантност към повреда, преди възстановяването да стане безнадеждно.
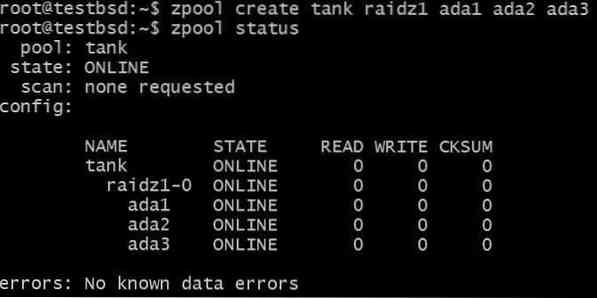
Нека създадем RAID-Z1 пул и да го развием:
$ zpool създайте резервоар raidz1 ada1 ada2 ada3
Пулът използва три 20GB диска, като 40GB от тях са достъпни за потребителя.
Добавянето на друг vdev ще изисква 3 допълнителни диска:
$ zpool добавете резервоар raidz1 ada4 ada5 ada6
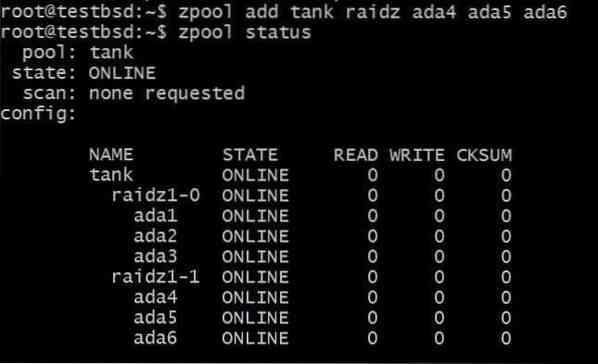
Общите използваеми данни вече са 80 GB и можете да загубите до 2 диска (по един от всеки vdev) и пак да имате надежда за възстановяване.
Заключение
Сега знаете достатъчно за ZFS, за да импортирате с увереност всичките си данни в него. Оттук нататък можете да търсите различни други функции, които ZFS предоставя, като използване на високоскоростни NVMes за четене и запис на кеш памет, използване на вградена компресия за вашите набори от данни и вместо да бъдете затрупани от всички налични опции, просто потърсете това, от което се нуждаете конкретен случай на употреба.
Междувременно има още няколко полезни съвета относно избора на хардуер, който трябва да следвате:
- Никога не използвайте хардуерен RAID-контролер със ZFS.
- Коригирането на RAM (ECC) за грешки се препоръчва, но не е задължително
- Функцията за дедупликация на данни отнема много памет, вместо това използвайте компресия.
- Излишъкът на данни не е алтернатива за архивиране. Имате няколко резервни копия, съхранявайте тези архиви, използвайки ZFS!


