Apache Hadoop е решение за големи данни за съхранение и анализ на големи количества данни. В тази статия ще разкажем подробно сложните стъпки за настройка на Apache Hadoop, за да започнете възможно най-бързо с него в Ubuntu. В тази публикация ще инсталираме Apache Hadoop на Ubuntu 17.10 машина.
Версия на Ubuntu
За това ръководство ще използваме Ubuntu версия 17.10 (GNU / Linux 4.13.0-38-генеричен x86_64).
Актуализиране на съществуващите пакети
За да стартирате инсталацията на Hadoop, е необходимо да актуализираме нашата машина с най-новите налични софтуерни пакети. Можем да направим това с:
sudo apt-get update && sudo apt-get -y dist-upgradeТъй като Hadoop се основава на Java, трябва да го инсталираме на нашата машина. Можем да използваме всяка версия на Java над Java 6. Тук ще използваме Java 8:
sudo apt-get -y инсталирай openjdk-8-jdk-headlessИзтегляне на Hadoop файлове
Всички необходими пакети вече съществуват на нашата машина. Готови сме да изтеглим необходимите TAR файлове на Hadoop, за да можем да започнем да ги настройваме и да стартираме и примерна програма с Hadoop.
В това ръководство ще инсталираме Hadoop v3.0.1. Изтеглете съответните файлове с тази команда:
wget http: // огледало.cc.Колумбия.edu / pub / software / apache / hadoop / common / hadoop-3.0.1 / хадооп-3.0.1.катран.gzВ зависимост от скоростта на мрежата това може да отнеме до няколко минути, тъй като файлът е голям по размер:
Изтегляне на Hadoop
Намерете най-новите двоични файлове на Hadoop тук. След като изтеглихме файла TAR, можем да извлечем в текущата директория:
tar xvzf hadoop-3.0.1.катран.gzТова ще отнеме няколко секунди, за да завършите поради големия размер на файла на архива:
Разархивиран Hadoop
Добавена е нова потребителска група на Hadoop
Тъй като Hadoop работи през HDFS, нова файлова система може да наруши и нашата собствена файлова система на машината на Ubuntu. За да избегнем това колисиране, ще създадем напълно отделна потребителска група и ще я присвоим на Hadoop, така че да съдържа свои собствени разрешения. С тази команда можем да добавим нова потребителска група:
addgroup hadoopЩе видим нещо като:
Добавяне на група потребители на Hadoop
Готови сме да добавим нов потребител към тази група:
useradd -G hadoop hadoopuserМоля, обърнете внимание, че всички команди, които изпълняваме, са като самия потребител на root. С командата aove успяхме да добавим нов потребител към групата, която създадохме.
За да позволим на потребителя на Hadoop да извършва операции, трябва да му предоставим и root достъп. Отвори / etc / sudoers файл с тази команда:
sudo visudoПреди да добавим нещо, файлът ще изглежда така:
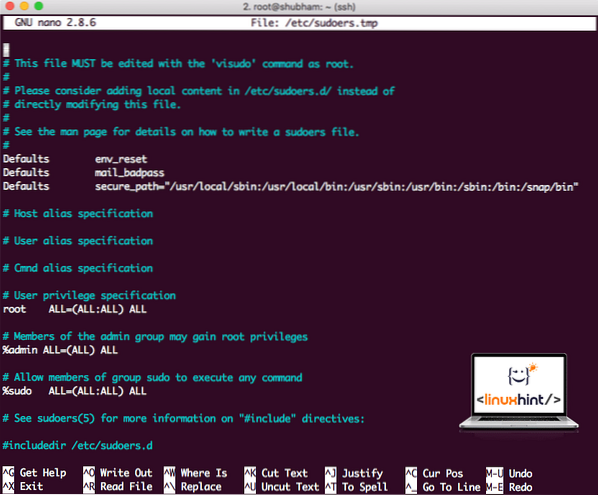
Файл Sudoers преди да добавите каквото и да било
Добавете следния ред в края на файла:
hadoopuser ALL = (ALL) ALLСега файлът ще изглежда така:
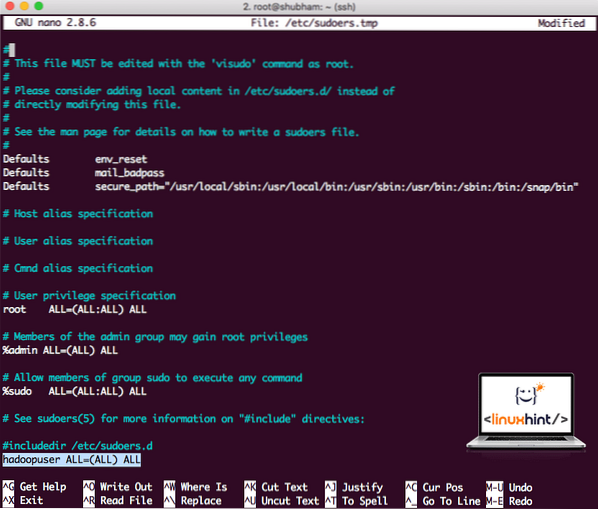
Файл Sudoers след добавяне на потребител на Hadoop
Това беше основната настройка за предоставяне на Hadoop платформа за извършване на действия. Готови сме да настроим един възел Hadoop клъстер сега.
Настройка на единичен възел Hadoop: Самостоятелен режим
Когато става въпрос за истинската мощ на Hadoop, той обикновено се настройва на множество сървъри, така че да може да се мащабира върху голямо количество данни, присъстващи в Разпределена файлова система Hadoop (HDFS). Това обикновено е добре при среди за отстраняване на грешки и не се използва за производствена употреба. За да улесним процеса, ще обясним как можем да направим настройка на един възел за Hadoop тук.
След като приключим с инсталирането на Hadoop, ще стартираме и примерно приложение на Hadoop. Към момента файлът Hadoop се нарича hadoop-3.0.1. нека го преименуваме на hadoop за по-проста употреба:
mv hadoop-3.0.1 хадопФайлът сега изглежда така:
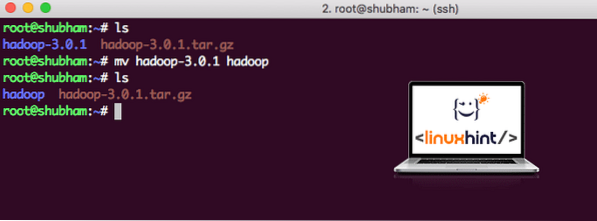
Преместване на Hadoop
Време е да се възползваме от потребителя на hadoop, който създадохме по-рано, и да възложим собствеността върху този файл на този потребител:
chown -R hadoopuser: хадооп / корен / хадоопПо-добро местоположение за Hadoop ще бъде / usr / local / директорията, така че нека го преместим там:
mv hadoop / usr / local /cd / usr / local /
Добавяне на Hadoop към Path
За да изпълним скриптове Hadoop, ще го добавим към пътя сега. За да направите това, отворете файла bashrc:
vi ~ /.bashrcДобавете тези редове в края на .bashrc, така че пътят да може да съдържа пътя на изпълнимия файл на Hadoop:
# Конфигурирайте Hadoop и Java Homeизнос HADOOP_HOME = / usr / local / hadoop
експортирайте JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64
износ PATH = $ PATH: $ HADOOP_HOME / bin
Файлът изглежда така:
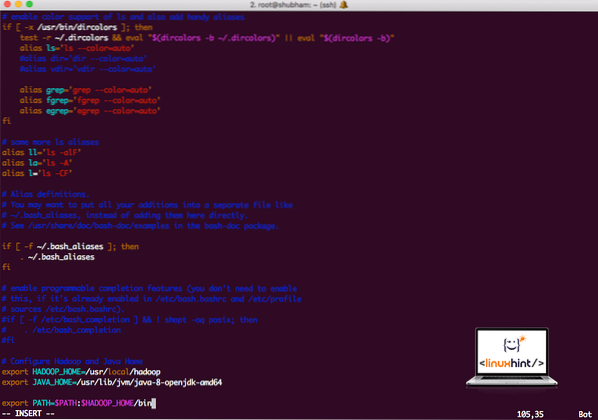
Добавяне на Hadoop към Path
Тъй като Hadoop използва Java, трябва да кажем на файла на средата Hadoop hadoop-env.ш където се намира. Местоположението на този файл може да варира в зависимост от версиите на Hadoop. За да намерите лесно къде се намира този файл, изпълнете следната команда точно извън директорията на Hadoop:
намирам hadoop / -name hadoop-env.шЩе получим изхода за местоположението на файла:
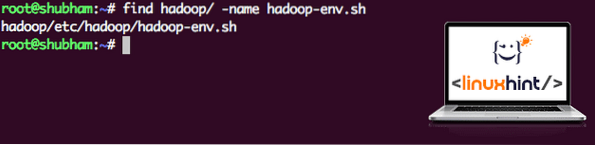
Местоположение на файла на околната среда
Нека редактираме този файл, за да информираме Hadoop за местоположението на Java JDK и да го вмъкнем в последния ред на файла и да го запазим:
експортирайте JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64Инсталацията и настройката на Hadoop вече са завършени. Готови сме да стартираме нашето примерно приложение сега. Но изчакайте, ние никога не сме правили примерна молба!
Стартиране на примерно приложение с Hadoop
Всъщност инсталирането на Hadoop се предлага с вградено примерно приложение, което е готово за стартиране, след като приключим с инсталирането на Hadoop. Звучи добре, нали?
Изпълнете следната команда, за да стартирате примера на JAR:
hadoop jar / root / hadoop / share / hadoop / mapreduce / hadoop-mapreduce-examples-3.0.1.jar wordcount / root / hadoop / README.txt / root / изходHadoop ще покаже колко обработка е направила на възела:
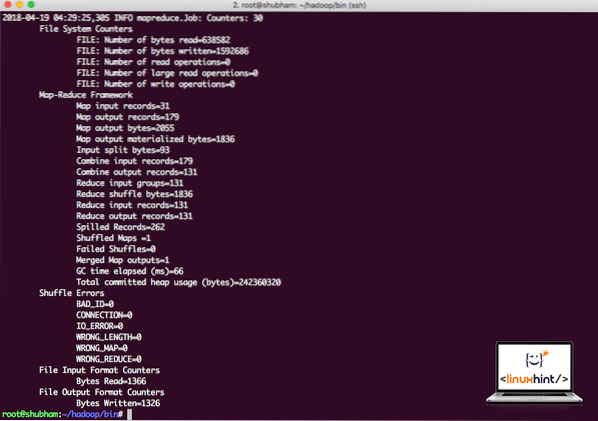
Статистика за обработка на Hadoop
След като изпълните следната команда, ние виждаме файла part-r-00000 като изход. Продължете и погледнете съдържанието на резултата:
котка част-r-00000Ще получите нещо като:
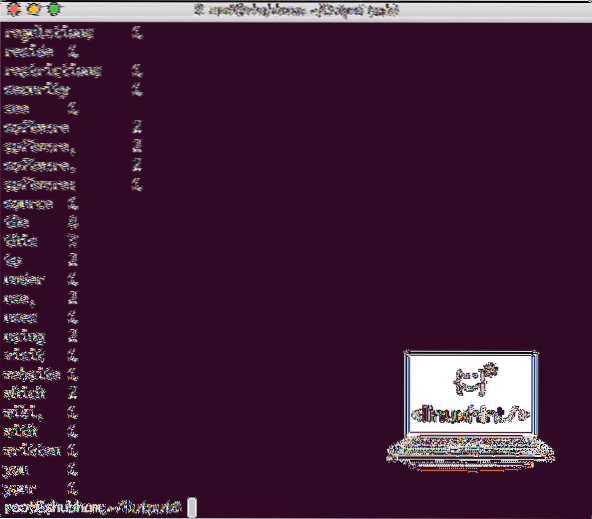
Извеждане на брой думи от Hadoop
Заключение
В този урок разгледахме как можем да инсталираме и да започнем да използваме Apache Hadoop на Ubuntu 17.10 машина. Hadoop е чудесен за съхраняване и анализ на огромно количество данни и се надявам тази статия да ви помогне бързо да започнете да го използвате на Ubuntu бързо.


