В тази статия ще разгледаме основните употреби на група по функция в python на panda. Всички команди се изпълняват в редактора на Pycharm.
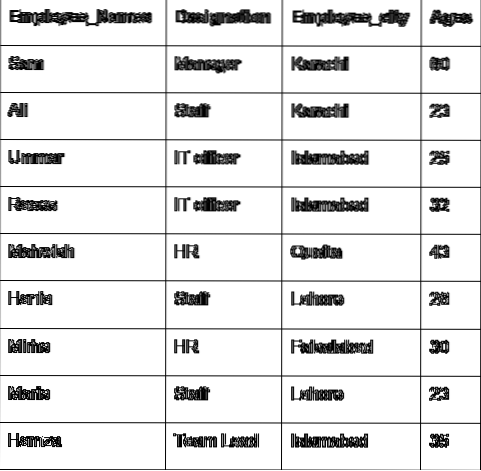
Нека обсъдим основната концепция на групата с помощта на данните на служителя. Създадохме кадър с някои полезни подробности за служителите (Employee_Names, Designation, Employee_city, Age).
Конкатенация на низове с помощта на Group by Function
С помощта на функцията groupby можете да обединявате низове. Същите записи могат да бъдат обединени с ',' в една клетка.
Пример
В следващия пример сме сортирали данни въз основа на колоната „Определение“ на служителите и сме се присъединили към служителите, които имат същото наименование. Ламбда функцията се прилага върху „Employees_Name“.
импортирайте панди като pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Назначение“: [„Мениджър“, „Персонал“, „ИТ служител“, „ИТ служител“, „HR“, „Персонал“, „HR“, „Персонал“, „Ръководител на екип“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Служител_Възраст“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
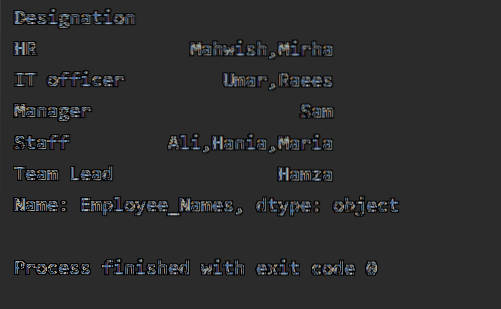
df1 = df.groupby ("Обозначение") ['Имена на служителите'].кандидатствайте (lambda Employee_Names: ','.присъединете се (Employee_Names))
печат (df1)
Когато се изпълни горният код, се показва следният изход:
Сортиране на стойности във възходящ ред
Използвайте обекта groupby в обикновен кадър от данни, като извикате '.to_frame () 'и след това използвайте reset_index () за повторно индексиране. Сортирайте стойностите на колоните чрез извикване на sort_values ().
Пример
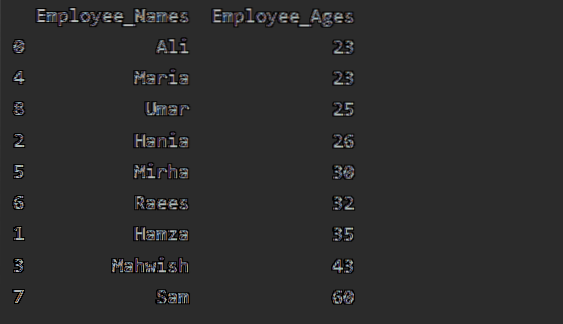
В този пример ще сортираме възрастта на служителя във възходящ ред. Използвайки следната част от кода, ние извличаме „Employee_Age“ във възходящ ред с „Employee_Names“.
импортирайте панди като pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Назначение“: [„Мениджър“, „Персонал“, „ИТ служител“, „ИТ служител“, „HR“, „Персонал“, „HR“, „Персонал“, „Ръководител на екип“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Служител_Възраст“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].сума ().to_frame ().reset_index ().сортиране_ценности (от = 'Служител_Възраст')
печат (df1)
Използване на агрегати с groupby
Налични са редица функции или обобщения, които можете да приложите върху групи данни, като count (), sum (), mean (), median (), mode (), std (), min (), max ().
Пример
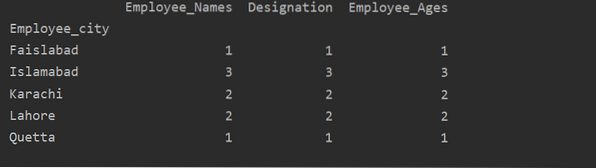
В този пример използвахме функция „count ()“ с groupby, за да преброим служителите, които принадлежат към същия „Employee_city“.
импортирайте панди като pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Назначение“: [„Мениджър“, „Персонал“, „ИТ служител“, „ИТ служител“, „HR“, „Персонал“, „HR“, „Персонал“, „Ръководител на екип“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Служител_Възраст“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city').броя()
печат (df1)
Както можете да видите следния изход, под колоните Designation, Employee_Names и Employee_Age пребройте числата, които принадлежат към същия град:
Визуализирайте данните с помощта на groupby
С помощта на 'import matplotlib.pyplot ', можете да визуализирате данните си в графики.
Пример
Тук следващият пример визуализира „Employee_Age“ с „Employee_Nmaes“ от дадената DataFrame с помощта на оператора groupby.
импортирайте панди като pdимпортиране на matplotlib.pyplot като plt
dataframe = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Назначение“: [„Мениджър“, „Персонал“, „ИТ служител“, „ИТ служител“, „HR“, „Персонал“, „HR“, „Персонал“, „Ръководител на екип“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Служител_Възраст“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
рамка за данни.groupby ('Employee_Names').сума ().парцел (вид = 'бар')
plt.покажи ()
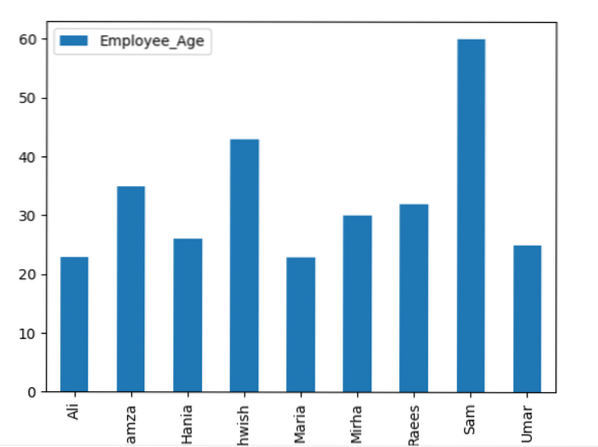
Пример
За да начертаете подредената графика с помощта на groupby, завъртете 'stacked = true' и използвайте следния код:
импортирайте панди като pdимпортиране на matplotlib.pyplot като plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Назначение“: [„Мениджър“, „Персонал“, „ИТ служител“, „ИТ служител“, „HR“, „Персонал“, „HR“, „Персонал“, „Ръководител на екип“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Служител_Възраст“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby (['Employee_city', 'Employee_Names']).размер ().дестакиране ().парцел (kind = 'bar', stacked = True, fontsize = '6')
plt.покажи ()
В дадената по-долу графика броят на заетите служители, които принадлежат към същия град.
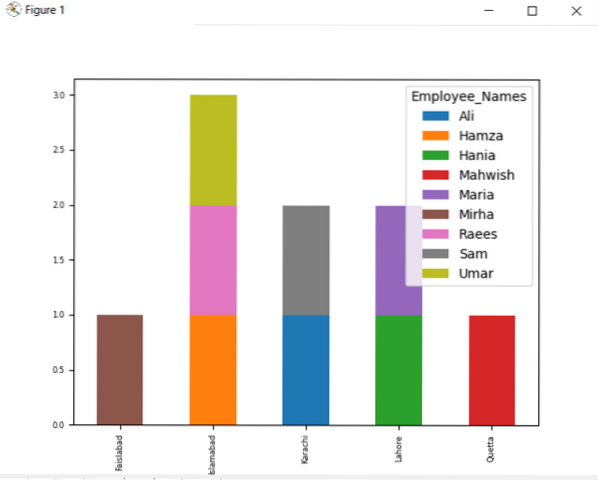
Променете името на колоната с групата по
Можете също така да промените обобщеното име на колона с ново модифицирано име, както следва:
импортирайте панди като pdимпортиране на matplotlib.pyplot като plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Назначение“: [„Мениджър“, „Персонал“, „ИТ служител“, „ИТ служител“, „HR“, „Персонал“, „HR“, „Персонал“, „Ръководител на екип“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Служител_Възраст“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Обозначение'].сума ().reset_index (name = 'Employee_Designation')
печат (df1)
В горния пример името „Обозначение“ се променя на „Employee_Designation“.
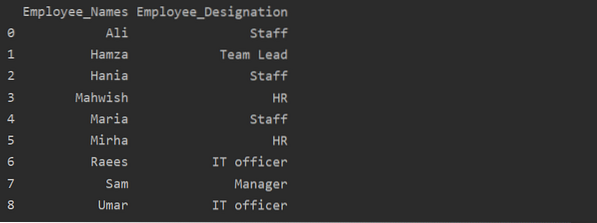
Извличане на група по ключ или стойност
Използвайки оператора groupby, можете да извлечете подобни записи или стойности от рамката с данни.
Пример
В дадения по-долу пример имаме групови данни въз основа на „Обозначение“. След това групата „Персонал“ се извлича с помощта на .getgroup ('Персонал').
импортирайте панди като pdимпортиране на matplotlib.pyplot като plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Назначение“: [„Мениджър“, „Персонал“, „ИТ служител“, „ИТ служител“, „HR“, „Персонал“, „HR“, „Персонал“, „Ръководител на екип“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Служител_Възраст“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
извличане_стойност = df.groupby („Обозначение“)
отпечатване (екстракция_стойност.get_group ('Персонал'))
Следният резултат се показва в изходния прозорец:

Добавяне на стойност в списъка с групи
Подобни данни могат да бъдат показани под формата на списък с помощта на оператора groupby. Първо групирайте данните въз основа на условие. След това, като приложите функцията, можете лесно да включите тази група в списъците.
Пример
В този пример сме вмъкнали подобни записи в списъка с групи. Всички служители са разделени в групата въз основа на 'Employee_city' и след това чрез прилагане на функцията 'Lambda' тази група се извлича под формата на списък.
импортирайте панди като pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Назначение“: [„Мениджър“, „Персонал“, „ИТ служител“, „ИТ служител“, „HR“, „Персонал“, „HR“, „Персонал“, „Ръководител на екип“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Служител_Възраст“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].кандидатстване (lambda group_series: group_series.tolist ()).reset_index ()
печат (df1)
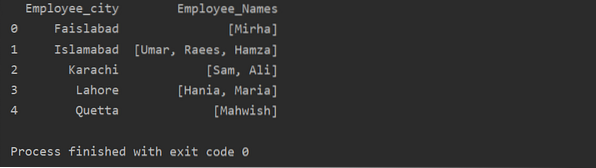
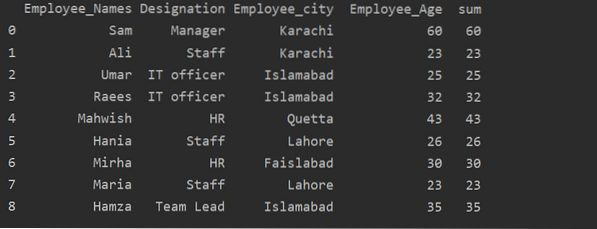
Използване на функцията за преобразуване с groupby
Служителите са групирани според възрастта им, тези стойности се събират и с помощта на функцията „преобразуване“ се добавя нова колона в таблицата:
импортирайте панди като pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Назначение“: [„Мениджър“, „Персонал“, „ИТ служител“, „ИТ служител“, „HR“, „Персонал“, „HR“, „Персонал“, „Ръководител на екип“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Служител_Възраст“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['сума'] = df.groupby (['Employee_Names']) ['Employee_Age'].преобразуване ('сума')
печат (df)
Заключение
В тази статия разгледахме различните приложения на оператора groupby. Показахме как можете да разделите данните на групи и като прилагате различни обобщения или функции, можете лесно да извлечете тези групи.


