В тази статия ще ви покажа как да намирате и избирате елементи от уеб страници, като използвате текст в Selenium с библиотеката на Python на Selenium. И така, нека започнем.
Предпоставки:
За да изпробвате командите и примерите от тази статия, трябва да имате:
- Линукс дистрибуция (за предпочитане Ubuntu), инсталирана на вашия компютър.
- Python 3, инсталиран на вашия компютър.
- PIP 3, инсталиран на вашия компютър.
- Python virtualenv пакет, инсталиран на вашия компютър.
- Mozilla Firefox или Google Chrome уеб браузъри, инсталирани на вашия компютър.
- Трябва да знаете как да инсталирате Firefox Gecko Driver или Chrome Web Driver.
За изпълнение на изискванията 4, 5 и 6 прочетете статията ми Въведение в селена в Python 3.
Можете да намерите много статии по другите теми на LinuxHint.com. Не забравяйте да ги проверите, ако имате нужда от помощ.
Създаване на директория на проекти:
За да поддържате всичко организирано, създайте нова директория на проекта селен-текст-избор / както следва:
$ mkdir -pv selenium-text-select / drivers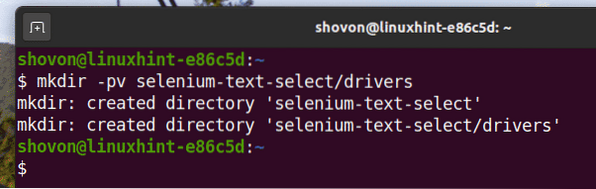
Придвижете се до селен-текст-избор / директория на проекта, както следва:
$ cd селен-текст-избор /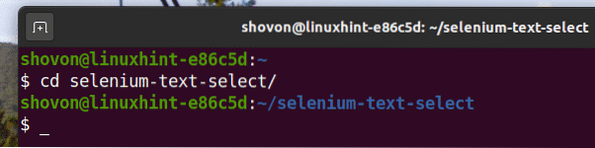
Създайте виртуална среда на Python в директорията на проекта, както следва:
$ virtualenv .venv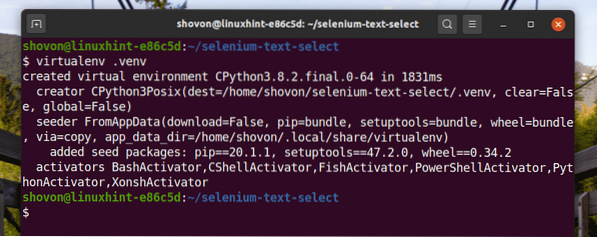
Активирайте виртуалната среда, както следва:
$ източник .venv / bin / активиране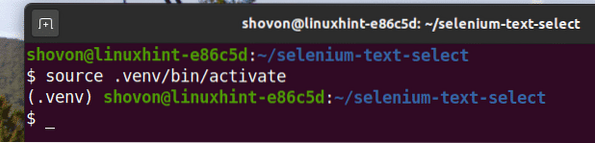
Инсталирайте библиотеката на Selenium Python, използвайки PIP3, както следва:
$ pip3 инсталиране на селен
Изтеглете и инсталирайте всички необходими уеб драйвери в шофьори / директория на проекта. Обясних процеса на изтегляне и инсталиране на уеб драйвери в моята статия Въведение в селена в Python 3.
Намиране на елементи по текст:
В този раздел ще ви покажа няколко примера за намиране и избор на елементи на уеб страница по текст с библиотеката Selenium Python.
Ще започна с най-простия пример за избор на елементи на уеб страница чрез текст, избиране на връзки от уеб страницата.
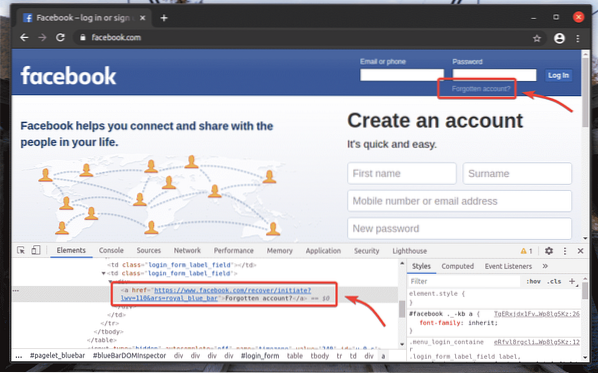
В страницата за вход на facebook.com, имаме връзка Забравен акаунт? Както можете да видите на екранната снимка по-долу. Нека да изберем тази връзка със Селен.
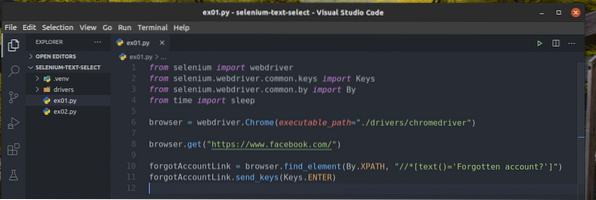
Създайте нов скрипт на Python ex01.py и въведете в него следните редове кодове.
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
от селен.уеб драйвер.често срещани.чрез импортиране от
от време внос сън
браузър = webdriver.Chrome (executable_path = "./ drivers / chromedriver ")
браузър.get ("https: // www.facebook.com / ")
ForgotAccountLink = браузър.find_element (от.XPATH, "
// * [text () = 'Забравен акаунт?'] ")
ForgotAccountLink.send_keys (Клавиши.ENTER)
След като приключите, запазете ex01.py Python скрипт.
Ред 1-4 импортира всички необходими компоненти в програмата Python.

Ред 6 създава Chrome браузър обект с помощта на хромедривър двоичен от шофьори / директория на проекта.

Ред 8 казва на браузъра да зареди facebook на уебсайта.com.

Ред 10 намира връзката, която съдържа текста Забравен акаунт? Използване на селектор XPath. За това използвах селектора XPath // * [text () = 'Забравен акаунт?'].
Селекторът XPath започва с //, което означава, че елементът може да бъде навсякъде на страницата. The * символът казва на Selenium да избере всеки етикет (а или стр или обхват, и т.н.), което съответства на условието в квадратните скоби []. Тук условието е, че текстът на елемента е равен на Забравен акаунт?

The текст() Функцията XPath се използва за получаване на текста на елемент.
Например, текст() се завръща Здравей свят ако избере следния HTML елемент.
Здравей святЛиния 11 изпраща

Стартирайте скрипта на Python ex01.py със следната команда:
$ python ex01.py
Както можете да видите, уеб браузърът намира, избира и натиска
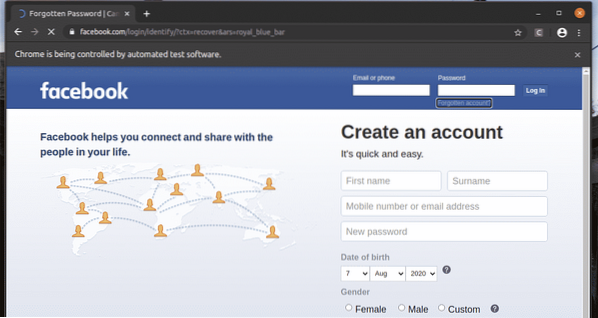
The Забравен акаунт? Връзката отвежда браузъра до следващата страница.
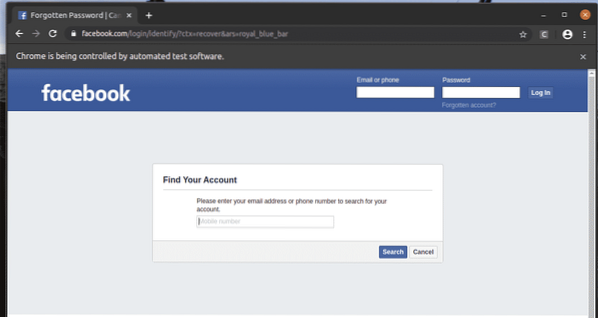
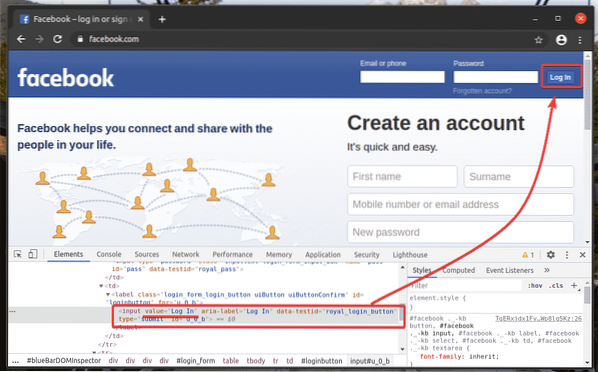
По същия начин можете лесно да търсите елементи, които имат желаната стойност на атрибута.
Ето, Влизам бутонът е вход елемент, който има стойност атрибут Влизам. Нека да видим как да изберем този елемент по текст.
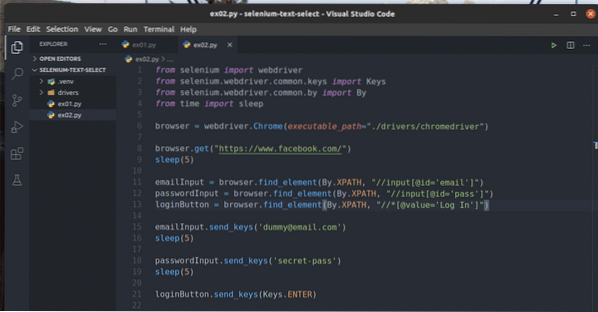
Създайте нов скрипт на Python ex02.py и въведете в него следните редове кодове.
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
от селен.уеб драйвер.често срещани.чрез импортиране от
от време внос сън
браузър = webdriver.Chrome (executable_path = "./ drivers / chromedriver ")
браузър.get ("https: // www.facebook.com / ")
сън (5)
emailInput = браузър.find_element (от.XPATH, "// вход [@ id = 'имейл']")
passwordInput = браузър.find_element (от.XPATH, "// вход [@ id = 'pass']")
loginButton = браузър.find_element (от.XPATH, "// * [@ value = 'Вход']")
emailInput.send_keys ('[имейл защитен]')
сън (5)
passwordInput.send_keys ('secret-pass')
сън (5)
бутон за вход.send_keys (Клавиши.ENTER)
След като приключите, запазете ex02.py Python скрипт.
Ред 1-4 импортира всички необходими компоненти.

Ред 6 създава Chrome браузър обект, използващ хромедривър двоично от шофьори / директория на проекта.

Ред 8 казва на браузъра да зареди facebook на уебсайта.com.
Всичко се случва толкова бързо, след като стартирате скрипта. И така, използвах сън () функционират много пъти в ex02.py за забавяне на командите на браузъра. По този начин можете да наблюдавате как всичко работи.

Ред 11 намира текстовото поле за въвеждане на имейл и съхранява препратка към елемента в emailInput променлива.

Ред 12 намира текстовото поле за въвеждане на имейл и съхранява препратка към елемента в emailInput променлива.

Ред 13 намира входния елемент, който има атрибута стойност на Влизам с помощта на XPath селектор. За това използвах селектора XPath // * [@ value = 'Log In'].
Селекторът XPath започва с //. Това означава, че елементът може да бъде навсякъде на страницата. The * символът казва на Selenium да избере всеки етикет (вход или стр или обхват, и т.н.), което съответства на условието в квадратните скоби []. Тук условието е атрибутът на елемента стойност е равно на Влизам.

Ред 15 изпраща входа [имейл защитен] до текстовото поле за въвеждане на имейл, а ред 16 отлага следващата операция.

Ред 18 изпраща входния таен пропуск към текстовото поле за въвеждане на парола и ред 19 отлага следващата операция.

Линия 21 изпраща

Стартирайте ex02.py Python скрипт със следната команда:
$ python3 ex02.py
Както можете да видите, текстовите полета за имейл и парола са пълни с нашите фиктивни стойности и Влизам бутонът е натиснат.
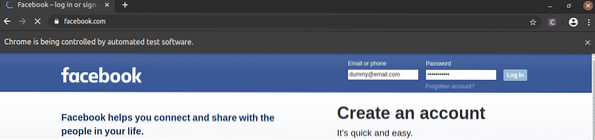
След това страницата се придвижва към следващата страница.
Намиране на елементи по частичен текст:
В по-ранния раздел ви показах как да намерите елементи по определен текст. В този раздел ще ви покажа как да намерите елементи от уеб страници, като използвате частичен текст.
В примера, ex01.py, Търсих елемента за връзка, който съдържа текста Забравен акаунт?. Можете да търсите същия елемент на връзка, като използвате частичен текст като Забравена съгл. За да направите това, можете да използвате съдържа() Функция XPath, както е показано на ред 10 от ex03.py. Останалите кодове са същите като в ex01.py. Резултатите ще бъдат същите.
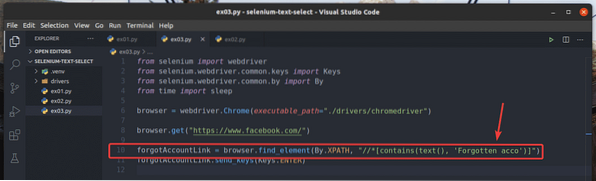
В ред 10 от ex03.py, условието за подбор използва съдържа (източник, текст) Функция XPath. Тази функция отнема 2 аргумента, източник, и текст.
The съдържа() функцията проверява дали текст даден във втория аргумент частично съвпада с източник стойност в първия аргумент.
Източникът може да бъде текстът на елемента (текст()) или стойността на атрибута на елемента (@attr_name).
В ex03.py, текстът на елемента се проверява.

Друга полезна функция XPath за намиране на елементи от уеб страницата с частичен текст е започва с (източник, текст). Тази функция има същите аргументи като съдържа() функция и се използва по същия начин. Единствената разлика е, че започва с() функция проверява дали вторият аргумент текст е началният низ на първия аргумент източник.
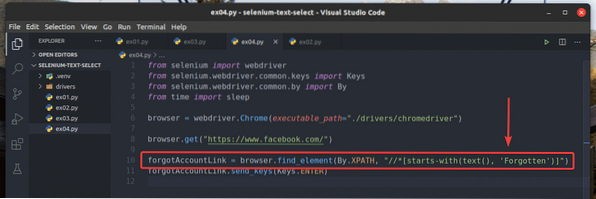
Пренаписах примера ex03.py за търсене на елемента, за който текстът започва Забравена, както можете да видите в ред 10 от ex04.py. Резултатът е същият като при ex02 и ex03.py.
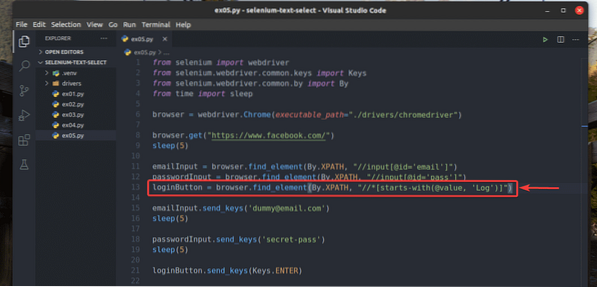
Аз също съм пренаписал ex02.py така че да търси входния елемент, за който стойност атрибут започва с Дневник, както можете да видите в ред 13 от ex05.py. Резултатът е същият като при ex02.py.
Заключение:
В тази статия ви показах как да намирате и избирате елементи от уеб страници по текст с библиотеката Selenium Python. Сега бихте могли да намирате елементи от уеб страници по специфичен текст или частичен текст с библиотеката Selenium Python.


