Големите данни са данни от порядъка на терабайта или петабайта и след това, състоящи се от добив, анализ и прогнозно моделиране на големи масиви от данни. Бързият растеж на информационните и технологични разработки предостави уникална възможност за физически лица и предприятия по целия свят да извличат печалби и да развиват нови възможности, предефиниращи традиционните бизнес модели, използвайки мащабен анализ.
Тази статия предоставя изглед от птичи поглед на пет от най-популярните платформи за данни с отворен код. Ето нашия списък:
Apache Hadoop
Apache Hadoop е софтуерна платформа с отворен код, която обработва много големи масиви от данни в разпределена среда по отношение на съхранението и изчислителната мощност и е основно изградена върху стоков хардуер с ниска цена.
Apache Hadoop е проектиран за лесно мащабиране от няколко до хиляди сървъри. Той ви помага да обработвате локално съхранени данни в цялостна паралелна настройка за обработка. Едно от предимствата на Hadoop е, че се справя с неуспехите на софтуерно ниво. Следващата фигура илюстрира цялостната архитектура на екосистемата Hadoop и къде са различните рамки в нея:
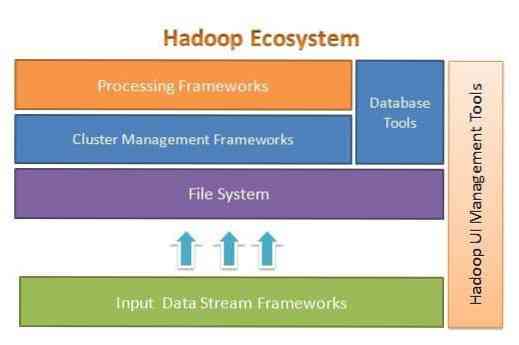
Apache Hadoop предоставя рамка за слоя на файловата система, слоя за управление на клъстери и слоя за обработка. Оставя възможност други проекти и рамки да дойдат и да работят заедно с екосистемата Hadoop и да разработят своя собствена рамка за всеки от слоевете, налични в системата.
Apache Hadoop се състои от четири основни модула. Тези модули са Hadoop Distributed File System (слой на файловата система), Hadoop MapReduce (който работи както с управлението на клъстера, така и с обработващия слой), Yet Another Resource Negotiator (YARN, слоят за управление на клъстера) и Hadoop Common.
Elasticsearch
Elasticsearch е пълна текстова машина за търсене и анализ. Това е силно мащабируема и разпределена система, специално проектирана да работи ефективно и бързо със системи за големи данни, където един от основните случаи на използване е анализ на регистрационните файлове. Той е в състояние да извършва разширени и сложни търсения и почти в реално време обработка за усъвършенстван анализ и оперативна информация.
Elasticsearch е написан на Java и е базиран на Apache Lucene. Издаден през 2010 г. и бързо набира популярност поради своята гъвкава структура на данните, мащабируема архитектура и много бързо време за реакция. Elasticsearch се основава на JSON документ със структура без схема, което прави осиновяването лесно и безпроблемно. Това е една от най-високо класираните търсачки от корпоративен клас. Можете да напишете неговия клиент на всеки език за програмиране; Elasticsearch официално работи с Java, .NET, PHP, Python, Perl и т.н.
Elasticsearch взаимодейства главно с помощта на REST API. Той получава данни под формата на JSON документи с всички необходими параметри и осигурява своя отговор по подобен начин.
MongoDB
MongoDB е база данни NoSQL, базирана на модела на данни за хранилището на документи. В MongoDB всичко е или колекция, или документ. За да разберем терминологията на MongoDB, колекцията е алтернативна дума за таблица, докато документът е алтернативна дума за редове.
MongoDB е база данни с отворен код, ориентирана към документи и междуплатформена база данни. Написано е основно на C++. Това е и водещата база данни NoSQL, която осигурява висока производителност, висока наличност и лесна мащабируемост. MongoDB използва JSON-подобни документи със схема и осигурява богата поддръжка на заявки. Някои от основните функции включват индексиране, репликация, балансиране на натоварването, агрегиране и съхранение на файлове.
Касандра
Cassandra е проект с отворен код Apache, предназначен за управление на база данни NoSQL. Редовете на Касандра са организирани в таблици и индексирани с ключ. Той използва механизъм за съхранение, базиран на журнали, само за добавяне. Данните в Cassandra се разпределят в множество безмастерни възли, без нито една точка на повреда. Това е проект на Apache от най-високо ниво и в момента неговото развитие се ръководи от Софтуерната фондация Apache (ASF).
Касандра е предназначена за решаване на проблеми, свързани с работата в голям (уеб) мащаб. Като се има предвид безкомплектната архитектура на Касандра, тя е в състояние да продължи да изпълнява операции въпреки малък (макар и значителен) брой хардуерни повреди. Касандра работи през множество възли в множество центрове за данни. Той възпроизвежда данни в тези центрове за данни, за да се избегне повреда или престой. Това го прави изключително устойчива на повреди система.
Касандра използва свой собствен програмен език за достъп до данни през своите възли. Нарича се Cassandra Query Language или CQL. Той е подобен на SQL, който се използва главно от релационни бази данни. CQL може да се използва чрез стартиране на собствено приложение, наречено cqlsh. Cassandra също така предлага много интеграционни интерфейси за множество програмни езици за изграждане на приложение, използващо Cassandra. Неговият API за интеграция поддържа Java, C ++, Python и други.
Apache HBase
HBase е друг проект на Apache, предназначен да управлява хранилището на данни NoSQL. Той е проектиран да използва характеристиките на Hadoop Ecosystem, включително надеждност, толерантност към грешки и т.н. Той използва HDFS като файлова система за съхранение. Съществуват множество модели данни, с които NoSQL работи и Apache HBase принадлежи към модела на данни, ориентиран към колона. HBase първоначално се базира на Google Big Table, който също е свързан с ориентирания към колони модел за неструктурирани данни.
HBase съхранява всичко под формата на двойка ключ-стойност. Важното е да се отбележи, че в HBase ключът и стойността са под формата на байтове. Така че, за да съхранявате каквато и да е информация в HBase, трябва да преобразувате информацията в байтове. (С други думи, неговият API не приема нищо друго освен масив от байтове.) Внимавайте с HBase, тъй като когато съхранявате данни, трябва да запомните оригиналния му тип. Данните, които първоначално са били низ, ще се върнат като байтов масив, ако бъдат извикани неправилно. В резултат на това ще създаде грешка във вашето приложение и ще го срине.
Надявам се тази статия да ви е харесала. Ако търсите да архитектирате и проектирате интензивни приложения за данни, тогава можете да разгледате Anuj Kumar's Архитектура на приложения, интензивни за данни. Това Книга е вашият шлюз за изграждане на интелигентни интензивни системи за данни чрез включване на основните интензивни архитектурни принципи, модели и техники, директно в архитектурата на вашето приложение.


