Apache Spark е инструмент за анализ на данни, който може да се използва за обработка на данни от HDFS, S3 или други източници на данни в паметта. В тази публикация ще инсталираме Apache Spark на Ubuntu 17.10 машина.
Версия на Ubuntu
За това ръководство ще използваме Ubuntu версия 17.10 (GNU / Linux 4.13.0-38-генеричен x86_64).
Apache Spark е част от екосистемата на Hadoop за големи данни. Опитайте да инсталирате Apache Hadoop и направете примерно приложение с него.
Актуализиране на съществуващите пакети
За да започнете инсталацията на Spark, е необходимо да актуализираме нашата машина с най-новите налични софтуерни пакети. Можем да направим това с:
sudo apt-get update && sudo apt-get -y dist-upgradeТъй като Spark се основава на Java, трябва да го инсталираме на нашата машина. Можем да използваме всяка версия на Java над Java 6. Тук ще използваме Java 8:
sudo apt-get -y инсталирай openjdk-8-jdk-headlessИзтегляне на Spark файлове
Всички необходими пакети вече съществуват на нашата машина. Готови сме да изтеглим необходимите Spark TAR файлове, за да можем да започнем да ги настройваме и да стартираме и примерна програма със Spark.
В това ръководство ще инсталираме Spark v2.3.0 налични тук:
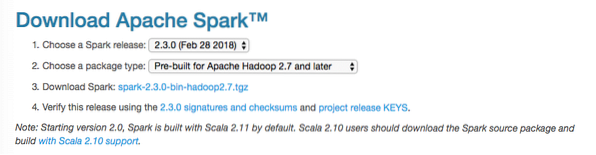
Страница за изтегляне на Spark
Изтеглете съответните файлове с тази команда:
wget http: // www-us.апаш.org / dist / искра / искра-2.3.0 / искра-2.3.0-bin-hadoop2.7.tgzВ зависимост от скоростта на мрежата това може да отнеме до няколко минути, тъй като файлът е голям по размер:
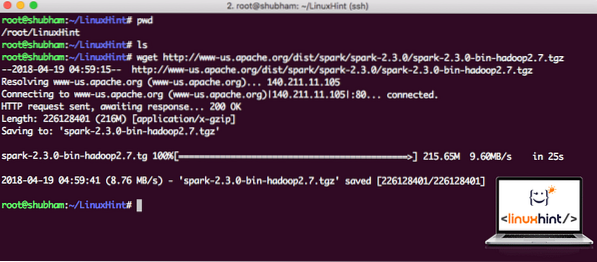
Изтегляне на Apache Spark
След като изтеглихме файла TAR, можем да извлечем в текущата директория:
tar xvzf искра-2.3.0-bin-hadoop2.7.tgzТова ще отнеме няколко секунди, за да завършите поради големия размер на файла на архива:
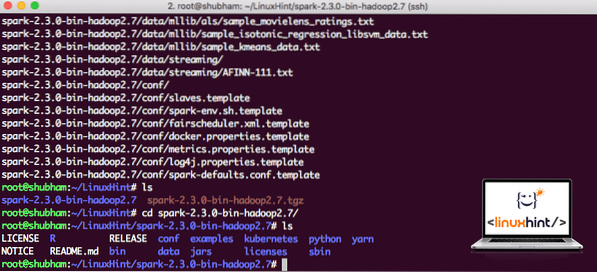
Разархивирани файлове в Spark
Когато става въпрос за надграждане на Apache Spark в бъдеще, това може да създаде проблеми поради актуализации на Path. Тези проблеми могат да бъдат избегнати чрез създаване на мека връзка към Spark. Изпълнете тази команда, за да направите мека връзка:
ln -s искра-2.3.0-bin-hadoop2.7 искраДобавяне на Spark към Path
За да изпълним Spark скриптове, сега ще го добавим към пътя. За да направите това, отворете файла bashrc:
vi ~ /.bashrcДобавете тези редове в края на .bashrc файл, така че пътят може да съдържа пътя на изпълнимия файл на Spark:
SPARK_HOME = / LinuxHint / искраизнос PATH = $ SPARK_HOME / bin: $ PATH
Сега файлът изглежда така:
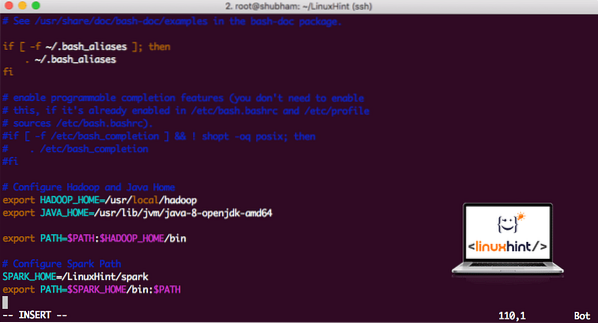
Добавяне на Spark към PATH
За да активирате тези промени, изпълнете следната команда за файл bashrc:
източник ~ /.bashrcСтартиране на Spark Shell
Сега, когато сме точно извън директорията на искрата, изпълнете следната команда, за да отворите обвивката на apark:
./ искра / кош / искра-черупкаЩе видим, че черупката на Spark се отваря и сега:
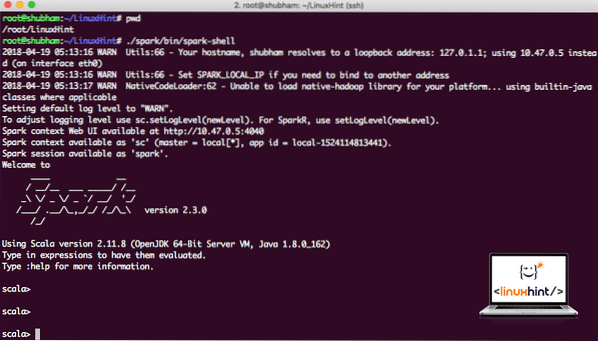
Стартиране на черупката Spark
В конзолата можем да видим, че Spark е отворил и Web Console на порт 404. Нека го посетим:
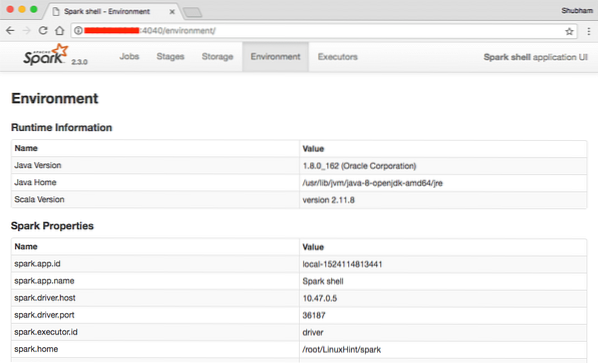
Уеб конзола Apache Spark
Въпреки че ще работим на самата конзола, уеб средата е важно място, на което трябва да обърнете внимание, когато изпълнявате тежки Spark Jobs, за да знаете какво се случва във всяка Spark Job, която изпълнявате.
Проверете версията на черупката Spark с проста команда:
sc.версияЩе получим обратно нещо като:
res0: низ = 2.3.0Изработване на примерно приложение Spark със Scala
Сега ще направим примерно приложение за брояч на думи с Apache Spark. За целта първо заредете текстов файл в контекста на Spark в черупката на Spark:
scala> var Data = sc.textFile ("/ root / LinuxHint / spark / README.md ")Данни: орг.апаш.искра.rdd.RDD [String] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] в textFile на: 24
скала>
Сега текстът във файла трябва да бъде разбит на символи, които Spark може да управлява:
scala> var tokens = Данни.flatMap (s => s.разделяне (""))жетони: орг.апаш.искра.rdd.RDD [String] = MapPartitionsRDD [2] при flatMap на: 25
скала>
Сега инициализирайте броя на всяка дума с 1:
scala> var tokens_1 = символи.карта (s => (s, 1))tokens_1: org.апаш.искра.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] на карта на: 25
скала>
И накрая, изчислете честотата на всяка дума от файла:
var sum_each = tokens_1.reduceByKey ((a, b) => a + b)Време е да разгледаме резултата за програмата. Съберете жетоните и съответното им броене:
scala> sum_each.събиране ()res1: Array [(String, Int)] = Array ((пакет, 1), (За, 3), (Програми, 1), (обработка.,1), (Защото, 1), (The, 1), (страница) (http: // искра.апаш.организация / документация.html).,1), (клъстер.,1), (си, 1), ([изпълнение, 1), (отколкото, 1), (API, 1), (има, 1), (Опитайте, 1), (изчисление, 1), (чрез, 1 ), (няколко, 1), (Това, 2), (графика, 1), (Кошера, 2), (съхранение, 1), (["Посочване, 1), (До, 2), (" прежда " , 1), (Веднъж, 1), (["Полезно, 1), (предпочитам, 1), (SparkPi, 2), (двигател, 1), (версия, 1), (файл, 1), (документация ,, 1), (обработка ,, 1), (на, 24), (са, 1), (системи.,1), (параметри, 1), (не, 1), (различно, 1), (вижте, 2), (Интерактивно, 2), (R ,, 1), (дадено.,1), (if, 4), (build, 4), (when, 1), (be, 2), (Tests, 1), (Apache, 1), (thread, 1), (programs ,, 1 ), (включително, 4), (./ bin / run-example, 2), (Spark.,1), (пакет.,1), (1000).count (), 1), (Версии, 1), (HDFS, 1), (D…
скала>
Отлично! Успяхме да стартираме прост пример за брояч на думи, използвайки програмен език Scala с текстов файл, който вече присъства в системата.
Заключение
В този урок разгледахме как можем да инсталираме и да започнем да използваме Apache Spark на Ubuntu 17.10 машина и стартирайте и пробно приложение на нея.
Прочетете повече публикации, базирани на Ubuntu тук.


