pip инсталирайте BeautifulSoup4
За да проверите дали инсталацията е била успешна, активирайте интерактивната обвивка на Python и импортирайте BeautifulSoup. Ако не се появи грешка, това означава, че всичко е минало добре. Ако не знаете как да го направите, въведете следните команди във вашия терминал.
$ pythonPython 3.5.2 (по подразбиране, 14 септември 2017 г., 22:51:06)
[GCC 5.4.0 20160609] на linux
Напишете "помощ", "авторско право", "кредити" или "лиценз" за повече информация.
>>> импортиране на bs4
За да работите с библиотеката BeautifulSoup, трябва да преминете в html. Когато работите с реални уебсайтове, можете да получите html на уеб страница, използвайки библиотеката за заявки. Инсталирането и използването на библиотеката за заявки е извън обхвата на тази статия, но можете да се ориентирате в документацията, че е доста лесна за използване. За тази статия ние просто ще използваме html в python низ, който бихме извикали html.
html = "" "[имейл защитен]
pparkerworks.com
""
За да използваме beautifulsoup, ние го импортираме в кода, използвайки кода по-долу:
от bs4 внос BeautifulSoupТова би въвело BeautifulSoup в нашето пространство от имена и ние можем да го използваме при анализирането на нашия низ.
супа = BeautifulSoup (html, "lxml")Сега, супа е обект BeautifulSoup от тип bs4.BeautifulSoup и можем да изпълним всички операции BeautifulSoup на супапроменлива.
Нека да разгледаме някои неща, които можем да направим с BeautifulSoup сега.
ПРАВИ ГРОЗНОТО, КРАСИВО
Когато BeautifulSoup анализира html, обикновено не е в най-добрия формат. Разстоянието е доста ужасно. Етикетите са трудни за намиране. Ето изображение, което показва как биха изглеждали, когато се отпечатате супа:
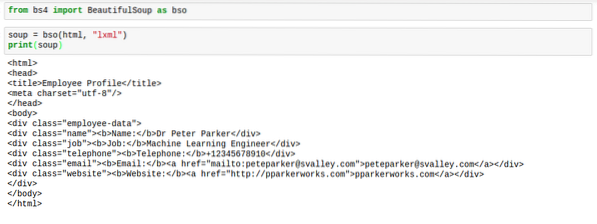
Решение за това обаче има. Решението дава на html перфектното разстояние, което прави нещата да изглеждат добре. Това решение заслужено се нарича „разкрасявам„.
Разбира се, може да не можете да използвате тази функция през повечето време; обаче има моменти, когато може да нямате достъп до инструмента за проверка на елемент на уеб браузър. В онези времена на ограничени ресурси бихте намерили метода на разкрасяването много полезен.
Ето как го използвате:
супа.красив ()Маркировката ще изглежда правилно разположена, точно както на изображението по-долу:
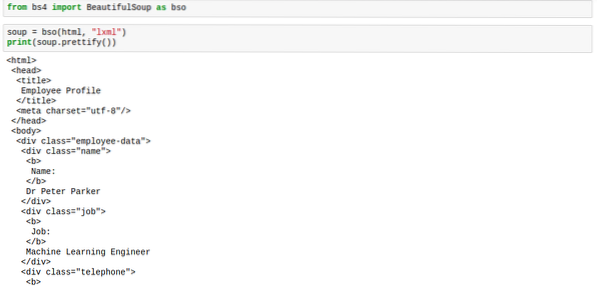
Когато приложите метода за разкрасяване на супата, резултатът вече не е тип bs4.BeautifulSoup. Резултатът вече е тип „unicode“. Това означава, че не можете да прилагате други методи BeautifulSoup върху него, но самата супа не е засегната, така че сме в безопасност.
НАМИРАНЕ НА ЛЮБИМИТЕ НИ МАРКИ
HTML се състои от тагове. Той съхранява всичките си данни в тях и сред цялата тази бъркотия се крият данните, от които се нуждаем. По принцип това означава, че когато намерим правилните тагове, можем да получим това, от което се нуждаем.
И така, как да намерим правилните тагове? Използваме методите за намиране и намиране на всички на BeautifulSoup.
Ето как работят:
The намирам метод търси първия таг с необходимото име и връща обект от тип bs4.елемент.Етикет.
The find_all метод, от друга страна, търси всички тагове с необходимото име на маркера и ги връща като списък от тип bs4.елемент.Резултат. Всички елементи в списъка са от тип bs4.елемент.Етикет, за да можем да извършим индексиране в списъка и да продължим нашето красиво проучване на супата.
Нека видим малко код. Нека намерим всички тагове div:
супа.намери („div“)Ще получим следния резултат:
Проверявайки променливата html, ще забележите, че това е първият div таг.
супа.find_all („div“)Ще получим следния резултат:
[[имейл защитен]
pparkerworks.com
Той връща списък. Ако например искате третия таг div, стартирате следния код:
супа.find_all („div“) [2]Ще върне следното:
НАМИРАНЕ НА АТРИБУТИТЕ НА НАШИТЕ ЛЮБИМИ ЕТИКЕТИ
Сега, когато видяхме как да получим любимите си тагове, какво ще кажете за получаването на техните атрибути?
Може би в този момент си мислите: „За какво ни трябват атрибути?„. Е, много пъти повечето от данните, от които се нуждаем, ще бъдат имейл адреси и уебсайтове. Този вид данни обикновено са хипервръзки в уеб страници, като връзките са в атрибута „href“.
Когато извлечем необходимия таг, използвайки методите find или find_all, можем да получим атрибути чрез прилагане attrs. Това ще върне речник на атрибута и неговата стойност.
За да получим например атрибута на имейл, получаваме тагове, които заобикалят необходимата информация и направете следното.
супа.find_all („a“) [0].attrsКоето би върнало следния резултат:
'href': 'mailto: [имейл защитен]'Същото нещо за атрибута на уебсайта.
супа.find_all („a“) [1].attrsКоето би върнало следния резултат:
'href': 'http: // pparkerworks.com'Върнатите стойности са речници и може да се приложи нормален синтаксис на речника, за да се получат ключовете и стойностите.
ДА ВИДИМ РОДИТЕЛЯ И ДЕЦАТА
Навсякъде има етикети. Понякога искаме да знаем какви са детските тагове и какъв е родителският.
Ако още не знаете какво е родителски и дъщерен маркер, това кратко обяснение трябва да е достатъчно: родителският таг е непосредственият външен таг, а дъщерният е непосредственият вътрешен таг на въпросния маркер.
Разглеждайки нашия html, основният таг е родителският маркер на всички тагове div. Също така, удебеленият етикет и котвата са дъщери на div таговете, където е приложимо, тъй като не всички div тагове притежават закотвени тагове.
Така че можем да получим достъп до родителския маркер, като извикаме findParent метод.
супа.намиране ("div").findParent ()Това би върнало целия таг на тялото:
[имейл защитен]
pparkerworks.com
За да получим детския таг на четвъртия div таг, ние извикваме findChildren метод:
супа.find_all ("div") [4].findChildren ()Той връща следното:
[Уебсайт:, pparkerworks.com]КАКВО ИМА ЗА НАС?
Когато разглеждаме уеб страници, не виждаме маркери навсякъде на екрана. Всичко, което виждаме, е съдържанието на различните тагове. Ами ако искаме съдържанието на етикет, без всички ъглови скоби да правят живота неудобен? Това не е трудно, всичко, което бихме направили, е да се обадим get_text метод на избрания маркер и ние получаваме текста в маркера и ако в маркера има други тагове, той също получава техните текстови стойности.
Ето пример:
супа.намери ("тяло").get_text ()Това връща всички текстови стойности в маркера на тялото:
Име: Д-р Питър ПаркърРабота: инженер по машинно обучение
Телефон: +12345678910
Имейл: [имейл защитен]
Уебсайт: pparkerworks.com
ЗАКЛЮЧЕНИЕ
Това имаме за тази статия. Все пак има и други интересни неща, които могат да се направят с красива супа. Можете да проверите документацията или да използвате реж. (BeautfulSoup) върху интерактивната обвивка, за да видите списъка с операции, които могат да бъдат извършени върху обект BeautifulSoup. Това е всичко от мен днес, докато не пиша отново.


