За да разберете концепцията за пълнотекстово търсене, трябва да си припомните знанията за търсене на шаблони чрез ключовата дума LIKE. И така, да приемем таблица „човек“ в базата данни „тест“ със следните записи в нея.
>> ИЗБЕРЕТЕ * ОТ човек;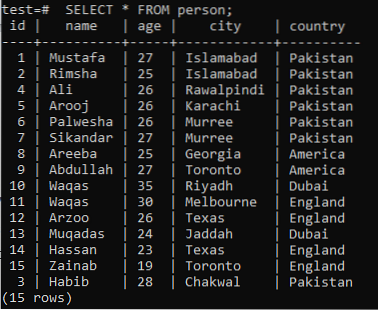
Да предположим, че искате да извлечете записите от тази таблица, където колоната „име“ има символ „i“ във всяка от стойностите си. Опитайте заявката по-долу SELECT, докато използвате клаузата LIKE в командната обвивка. От изхода по-долу можете да видите, че имаме само 5 записа за този конкретен символ „i“ в колоната „name“.
>> ИЗБЕРЕТЕ * ОТ човек КЪДЕ име КАТО „% i%“;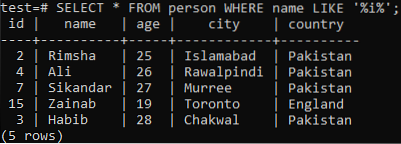
Употреба на Tvsector:
Понякога е безполезно да използвате ключовата дума LIKE за бързо търсене на шаблон, въпреки че думата е там. Може би бихте обмислили да използвате стандартни изрази и въпреки че това е осъществима алтернатива, регулярните изрази са едновременно силни и мудни. Наличието на процедурен вектор за цели думи в даден текст, народно описание на тези думи, е много по-ефективен начин за справяне с този проблем. Концепцията за пълно търсене на текст и типа данни tsvector е създадена, за да отговори на нея. В PostgreSQL има два метода, които правят точно това, което искаме:
- To_tvsector: Използва се за съставяне на списък с жетони (ts означава за „търсене на текст“).
- To_tsquery: Използва се за търсене във вектора за честота на конкретни термини или фрази.
Пример 01:
Нека започнем с проста илюстрация на създаването на вектор. Да предположим, че искате да направите вектор за струната: „Някои хора имат къдрава кестенява коса чрез правилно четкане.”. Така че трябва да напишете функция to_tvsector () заедно с това изречение в скобите на SELECT заявка, както е приложено по-долу. От изхода по-долу можете да видите, че той ще даде вектор на препратки (файлови позиции) за всеки маркер, а също и когато термини с малък контекст, като статии () и съединения (и, или), са умишлено игнорирани.
>> ИЗБЕРЕТЕ to_tsvector ('Някои хора имат къдрави кафяви косми чрез правилно четкане');
Пример 02:
Да предположим, че имате два документа с някои данни и в двата. За да съхраняваме тези данни, сега ще използваме реален пример за генериране на жетони. Да предположим, че сте създали таблица „Данни“ във вашата „база данни“ с някои колони в нея, като използвате заявката СЪЗДАВАНЕ НА ТАБЛИЦА по-долу. Не забравяйте да създадете колона тип TVSECTOR с име „token“ в нея. От изхода по-долу можете да погледнете таблицата, която е създадена.
>> СЪЗДАВАНЕ НА ТАБЛИЦА Данни (Id СЕРИАЛЕН ОСНОВЕН КЛЮЧ, информационен ТЕКСТ, токен TSVECTOR);
Сега се оказва, че добавяме общите данни на двата документа в тази таблица. Затова опитайте командата INSERT по-долу във вашата обвивка на командния ред, за да го направите. И накрая, записите от двата документа са успешно добавени в таблицата „Данни“.
>> ВЪВЕДЕТЕ В СТОЙНОСТИ за данни (информация) („Две грешки никога не могат да направят едно правилно.'), (' Той е този, който може да играе футбол.'), (' Мога ли да играя роля в това?'), (' Болката вътре в човек не може да бъде разбрана '), (' Внеси праскова в живота си);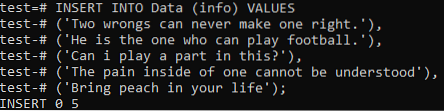
Сега трябва да колонизирате колоната с символи на двата документа с конкретния им вектор. В крайна сметка обикновена UPDATE заявка ще запълни колоната с маркери по съответния им вектор за всеки файл. Така че, трябва да изпълните заявката по-долу в командната обвивка, за да го направите. Резултатът показва, че актуализацията е направена най-накрая.
>> АКТУАЛИЗИРАНЕ на данни f1 SET token = to_tsvector (f1.информация) ОТ Данни f2;
Сега, когато разполагаме с всичко на място, нека се върнем към нашата илюстрация на „може ли един“ със сканиране. To_tsquery с оператор AND, както беше казано по-рано, не прави разлика между местоположенията на файловете във файловете, както е показано от изхода, посочен по-долу.
>> ИЗБЕРЕТЕ Id, информация ОТ Данни WHERE token @@ to_tsquery ('can & one');
Пример 04:
За да намерим думи, които са „една до друга“, ще опитаме същата заявка с „<->' оператор. Промяната се показва в изхода по-долу.
>> ИЗБЕРЕТЕ ИД, информация ОТ Данни WHERE токен @@ to_tsquery ('can <-> един ');
Ето пример за никаква непосредствена дума до друга.
>> ИЗБЕРЕТЕ Id, информация ОТ Данни WHERE token @@ to_tsquery ('one <-> болка ');
Пример 05:
Ще намерим думите, които не са непосредствено една до друга, като използваме число в оператора за разстояние, за да посочим разстоянието. Близостта между „донесе“ и „живот“ е само 4 думи, освен показаното изображение.
>> ИЗБЕРЕТЕ * ОТ Данни WHERE токен @@ to_tsquery ('донесе <4> живот ');
За да проверите близостта между думите за почти 5 думи, е добавено по-долу.
>> SELECT * FROM Data WHERE token @@ to_tsquery ('грешно <5> вдясно ');
Заключение:
И накрая, направихте всички прости и сложни примери за пълнотекстово търсене, използвайки операторите и функциите To_tvsector и to_tsquery.


