Например, бизнес може да стартира механизъм за текстов анализ, който обработва туитовете за неговия бизнес, като споменава името на компанията, местоположението, процеса и анализира емоцията, свързана с този туит. Правилните действия могат да бъдат предприети по-бързо, ако този бизнес се запознае с нарастващите негативни туитове за него на определено място, за да се спаси от гаф или нещо друго. Друг често срещан пример ще за Youtube. Администраторите и модераторите на YouTube се запознават с ефекта на видеоклипа в зависимост от вида коментари, направени към видеоклип или съобщенията във видео чата. Това ще им помогне да намират неподходящо съдържание на уебсайта много по-бързо, защото сега те са премахнали ръчната работа и са използвали автоматизирани ботове за интелигентен анализ на текст.
В този урок ще изучим някои от концепциите, свързани с анализ на текст с помощта на библиотеката NLTK в Python. Някои от тези понятия ще включват:
- Токенизация, как да разбиете парче текст на думи, изречения
- Избягване на думи за спиране въз основа на английски език
- Извършване на стеминг и лематизация върху парче текст
- Идентифициране на жетоните, които ще бъдат анализирани
НЛП ще бъде основната област на фокус в този урок, тъй като е приложима за огромни сценарии от реалния живот, където може да реши големи и решаващи проблеми. Ако смятате, че това звучи сложно, добре е, но понятията са еднакво лесни за разбиране, ако опитате примери рамо до рамо. Нека да преминем към инсталирането на NLTK на вашата машина, за да започнем с нея.
Инсталиране на NLTK
Само бележка преди започване, можете да използвате виртуална среда за този урок, която можем да направим със следната команда:
python -m virtualenv nltkизточник nltk / bin / активиране
След като виртуалната среда е активна, можете да инсталирате библиотека NLTK във виртуалната среда, така че примери, които създаваме след това, да могат да бъдат изпълнени:
pip инсталирайте nltkВ този урок ще използваме Анаконда и Юпитер. Ако искате да го инсталирате на вашата машина, погледнете урока, който описва „Как да инсталирате Anaconda Python на Ubuntu 18.04 LTS ”и споделете вашите отзиви, ако се сблъскате с някакви проблеми. За да инсталирате NLTK с Anaconda, използвайте следната команда в терминала от Anaconda:
conda install -c anaconda nltkВиждаме нещо подобно, когато изпълняваме горната команда:
След като всички необходими пакети са инсталирани и готови, можем да започнем с използването на библиотеката NLTK със следния оператор за импортиране:
внос nltkНека започнем с основните примери за NLTK сега, след като сме инсталирали пакетите за предварителни условия.
Токенизация
Ще започнем с токенизация, която е първата стъпка в извършването на анализ на текст. Токен може да бъде всяка по-малка част от текст, която може да бъде анализирана. Има два вида токенизация, които могат да се извършват с NLTK:
- Токенизация на изречението
- Токенизация на думи
Можете да познаете какво се случва при всяка от токенизацията, така че нека се потопим в примери за кодове.
Токенизация на изречението
Тъй като името отразява, Senkence Tokenizers разбива парче текст на изречения. Нека опитаме прост кодов фрагмент за същото, където използваме текст, който сме избрали от урока за Apache Kafka. Ще извършим необходимия внос
внос nltkот nltk.импортиране
Моля, обърнете внимание, че може да се сблъскате с грешка поради липсваща зависимост за извикания nltk точка. Добавете следния ред веднага след импортирането в програмата, за да избегнете предупреждения:
nltk.изтегляне ('punkt')За мен той даде следния изход:
След това използваме импортирания токенизатор на изречения:
text = "" "Тема в Kafka е нещо, където се изпраща съобщение. Потребителятприложения, които се интересуват от тази тема, привлича съобщението вътре в нея
тема и може да направи всичко с тези данни. До определен час, произволен брой
потребителските приложения могат да изтеглят това съобщение неограничен брой пъти.""
изречения = sent_tokenize (текст)
печат (изречения)
Виждаме нещо подобно, когато изпълняваме горния скрипт:

Както се очакваше, текстът беше правилно организиран в изречения.
Токенизация на думи
Тъй като името отразява, Word Tokenizers разбива парче текст на думи. Нека опитаме прост кодов фрагмент за същото със същия текст като предишния пример:
от nltk.импортиране на внос word_tokenizeдуми = word_tokenize (текст)
печат (думи)
Виждаме нещо подобно, когато изпълняваме горния скрипт:

Както се очакваше, текстът беше правилно организиран в думи.
Разпределение на честотата
След като разделихме текста, можем също да изчислим честотата на всяка дума в текста, който използвахме. Много е лесно да се направи с NLTK, ето кодовият фрагмент, който използваме:
от nltk.вероятност внос FreqDistразпределение = FreqDist (думи)
печат (разпространение)
Виждаме нещо подобно, когато изпълняваме горния скрипт:

След това можем да намерим най-често срещаните думи в текста с проста функция, която приема броя на думите за показване:
# Най-често срещани думиразпределение.най-често (2)
Виждаме нещо подобно, когато изпълняваме горния скрипт:

И накрая, можем да направим график за разпределение на честотата, за да изчистим думите и броя им в дадения текст и ясно да разберем разпределението на думите:

Stopwords
Точно както когато разговаряме с друг човек по време на разговор, обикновено има някакъв шум при разговора, който е нежелана информация. По същия начин текстът от реалния свят също съдържа шум, който се нарича като Stopwords. Stopwords може да варира от език на език, но те могат лесно да бъдат идентифицирани. Някои от Stopwords на английски език могат да бъдат - е, са, а, на, и т.н.
Можем да разгледаме думи, които се считат за Stopwords от NLTK за английски език със следния кодов фрагмент:
от nltk.стоп думи за внос на корпусnltk.изтегляне („stopwords“)
език = "английски"
stop_words = set (stopwords.думи (език))
печат (стоп_думи)
Тъй като разбира се наборът от думи за спиране може да бъде голям, той се съхранява като отделен набор от данни, който може да бъде изтеглен с NLTK, както показахме по-горе. Виждаме нещо подобно, когато изпълняваме горния скрипт:
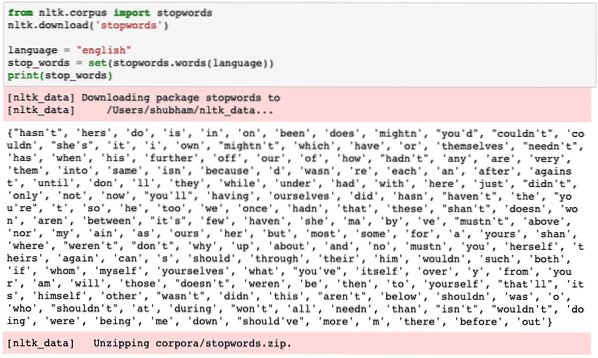
Тези думи за спиране трябва да бъдат премахнати от текста, ако искате да извършите точен анализ на текста за предоставеното парче текст. Нека премахнем стоп думите от нашите текстови символи:
filtered_words = []за дума в думи:
ако думата не е в stop_words:
filtered_words.добавяне (дума)
filtered_words
Виждаме нещо подобно, когато изпълняваме горния скрипт:

Слово за закръгляне
Стъблото на думата е основата на тази дума. Например:
Ще изпълним произтичащи от филтрираните думи, от които премахнахме думите за спиране в последния раздел. Нека напишем прост кодов фрагмент, където използваме стволовия код на NLTK, за да извършим операцията:
от nltk.импортиране на стволови PorterStemmerps = PorterStemmer ()
stemmed_words = []
за дума в filtered_words:
stemmed_words.добави (ps.стъбло (дума))
print ("Stemmed Sentence:", stemmed_words)
Виждаме нещо подобно, когато изпълняваме горния скрипт:

POS маркиране
Следващата стъпка в текстовия анализ е след изтичането е да се идентифицират и групират всяка дума по отношение на тяхната стойност, т.е.д. ако всяка от думата е съществително или глагол или нещо друго. Това се нарича част от маркирането на реч. Нека да извършим POS маркиране сега:
жетони = nltk.word_tokenize (изречения [0])печат (жетони)
Виждаме нещо подобно, когато изпълняваме горния скрипт:

Сега можем да извършим маркирането, за което ще трябва да изтеглим друг набор от данни, за да идентифицираме правилните маркери:
nltk.изтегляне ('усреднен_перцепт_маркер')nltk.pos_tag (символи)
Ето резултата от маркирането:
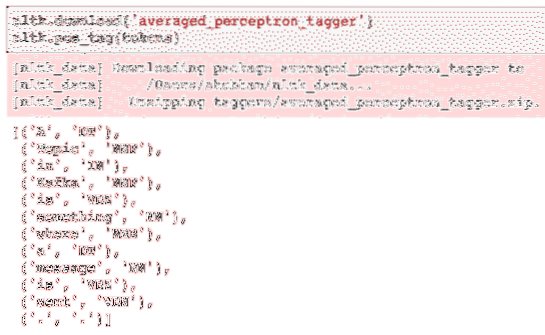
След като най-накрая идентифицирахме маркираните думи, това е наборът от данни, върху който можем да извършим анализ на настроенията, за да идентифицираме емоциите зад изречение.
Заключение
В този урок разгледахме отличен естествен езиков пакет, NLTK, който ни позволява да работим с неструктурирани текстови данни, за да идентифицираме всякакви стоп думи и да извършим по-задълбочен анализ, като подготвим остър набор от данни за текстов анализ с библиотеки като sklearn.
Намерете целия изходен код, използван в този урок на Github. Моля, споделете отзивите си за урока в Twitter с @sbmaggarwal и @LinuxHint.


