Тази статия ще ви покаже как да настроите Selenium във вашата Linux дистрибуция (т.е.д., Ubuntu), както и как да извършите основна уеб автоматизация и бракуване на уеб с библиотеката Selenium Python 3.
Предпоставки
За да изпробвате командите и примерите, използвани в тази статия, трябва да имате следното:
1) Линукс дистрибуция (за предпочитане Ubuntu), инсталирана на вашия компютър.
2) Python 3, инсталиран на вашия компютър.
3) PIP 3, инсталиран на вашия компютър.
4) Уеб браузърът Google Chrome или Firefox, инсталиран на вашия компютър.
Можете да намерите много статии по тези теми в LinuxHint.com. Не забравяйте да проверите тези статии, ако имате нужда от допълнителна помощ.
Подготовка на виртуалната среда на Python 3 за проекта
Виртуалната среда на Python се използва за създаване на изолирана директория на проекти на Python. Модулите Python, които инсталирате с помощта на PIP, ще бъдат инсталирани само в директорията на проекта, а не глобално.
Питонът virtualenv модул се използва за управление на виртуални среди на Python.
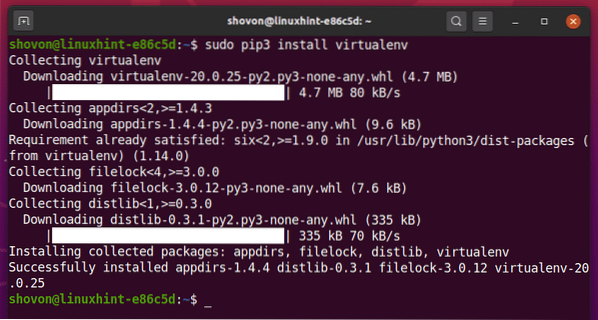
Можете да инсталирате Python virtualenv модул, използващ глобално PIP 3, както следва:
$ sudo pip3 инсталира virtualenv
PIP3 ще изтегли и инсталира глобално всички необходими модули.

На този етап Python virtualenv модул трябва да се инсталира глобално.
Създайте директорията на проекта питон-селен-основен / в текущата работна директория, както следва:
$ mkdir -pv python-selenium-basic / драйвери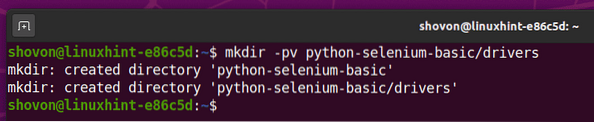
Придвижете се до новосъздадената директория на проекта питон-селен-основен /, както следва:
$ cd python-селен-основен /
Създайте виртуална среда на Python във вашата директория на проекта със следната команда:
$ virtualenv .env
Виртуалната среда на Python сега трябва да бъде създадена във вашата директория на проекта.'

Активирайте виртуалната среда на Python във вашата директория на проекта чрез следната команда:
$ източник .env / bin / активиране
Както можете да видите, виртуалната среда на Python е активирана за тази директория на проекта.

Инсталиране на библиотека Selenium Python
Библиотеката на Selenium Python се предлага в официалното хранилище на Python PyPI.
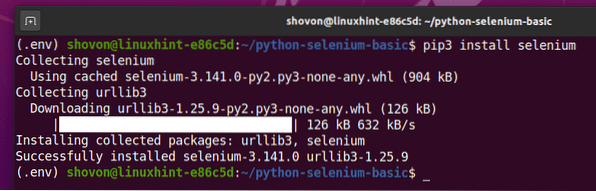
Можете да инсталирате тази библиотека с помощта на PIP 3, както следва:
$ pip3 инсталиране на селен
Би трябвало да бъде инсталирана библиотеката на Selenium Python.
След като библиотеката Selenium Python е инсталирана, следващото нещо, което трябва да направите, е да инсталирате уеб драйвер за любимия си уеб браузър. В тази статия ще ви покажа как да инсталирате уеб драйверите на Firefox и Chrome за Selenium.
Инсталиране на драйвер за Firefox Gecko
Драйверът за Firefox Gecko ви позволява да контролирате или автоматизирате уеб браузъра Firefox, използвайки Selenium.
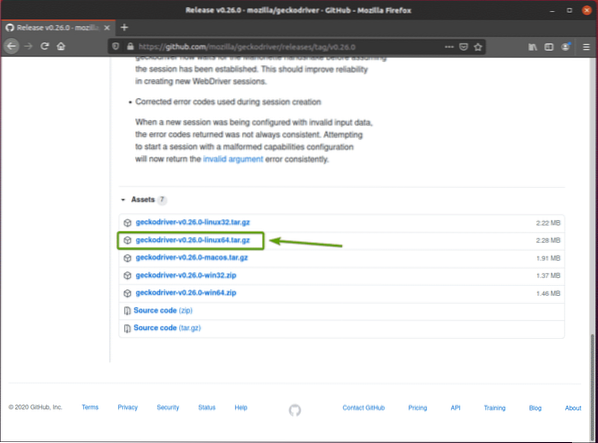
За да изтеглите драйвера за Firefox Gecko, посетете страницата за издания на GitHub на mozilla / geckodriver от уеб браузър.
Както можете да видите, v0.26.0 е най-новата версия на Firefox Gecko Driver към момента на писане на тази статия.
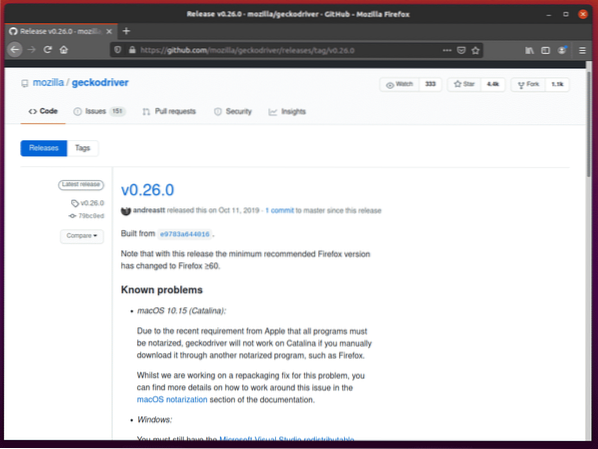
За да изтеглите драйвера за Firefox Gecko, превъртете малко надолу и щракнете върху Linux geckodriver tar.gz архив, в зависимост от архитектурата на вашата операционна система.
Ако използвате 32-битова операционна система, щракнете върху geckodriver-v0.26.0-linux32.катран.gz връзка.
Ако използвате 64-битова операционна система, щракнете върху geckodriver-v0.26.0-linuxx64.катран.gz връзка.
В моя случай ще изтегля 64-битовата версия на Firefox Gecko Driver.
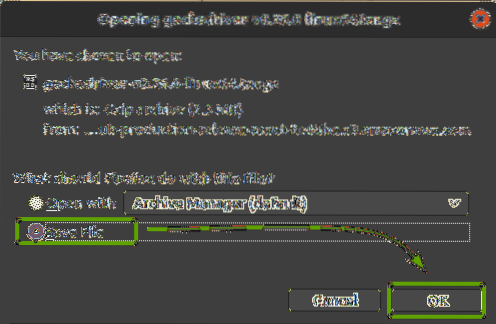
Вашият браузър трябва да ви подкани да запазите архива. Изберете Запишете файла и след това щракнете Добре.
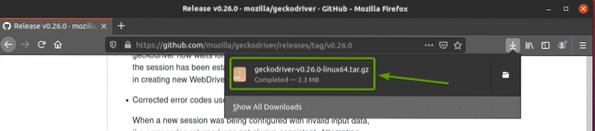
Архивът на Firefox Gecko Driver трябва да бъде изтеглен в ~ / Изтегляния директория.
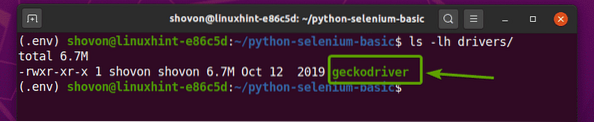
Извлечете geckodriver-v0.26.0-linux64.катран.gz архив от ~ / Изтегляния директория към шофьори / директория на вашия проект, като въведете следната команда:
$ tar -xzf ~ / Downloads / geckodriver-v0.26.0-linux64.катран.gz -C драйвери /
След като архивът на Firefox Gecko Driver бъде извлечен, нов geckodriver двоичен файл трябва да бъде създаден в шофьори / директория на вашия проект, както можете да видите на екранната снимка по-долу.
Тестване на драйвер за селен Firefox Gecko
В този раздел ще ви покажа как да настроите първия си скрипт на Selenium Python, за да тествате дали Firefox Gecko Driver работи.
Първо отворете директорията на проекта питон-селен-основен / с любимата си IDE или редактор. В тази статия ще използвам Visual Studio Code.
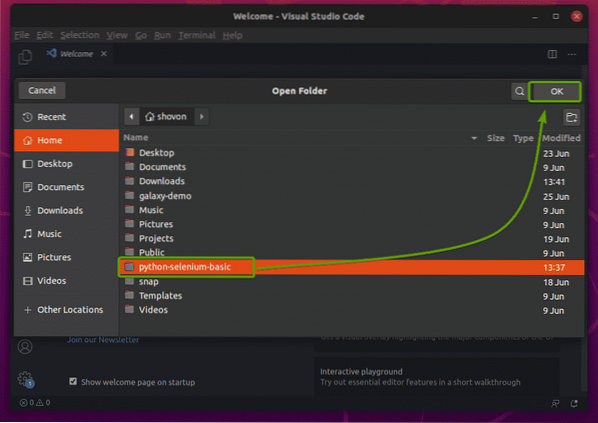
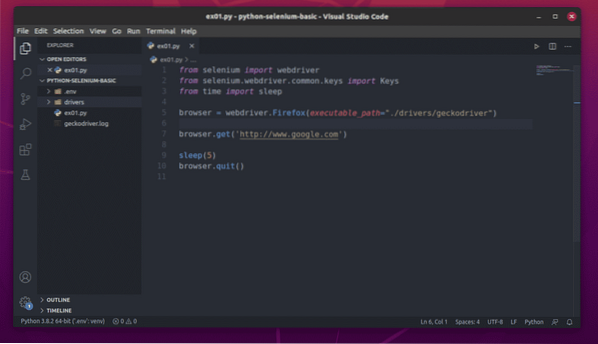
Създайте новия скрипт на Python ex01.py, и въведете следните редове в скрипта.
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
от време внос сън
браузър = webdriver.Firefox (изпълним_ път = "./ drivers / geckodriver ")
браузър.get ('http: // www.google.com ')
сън (5)
браузър.изход ()
След като приключите, запазете ex01.py Python скрипт.
Ще обясня кода в следващ раздел на тази статия.
Следващият ред конфигурира Selenium да използва Firefox Gecko Driver от шофьори / директория на вашия проект.

За да проверите дали Firefox Gecko Driver работи с Selenium, изпълнете следното ex01.py Python скрипт:
$ python3 ex01.py
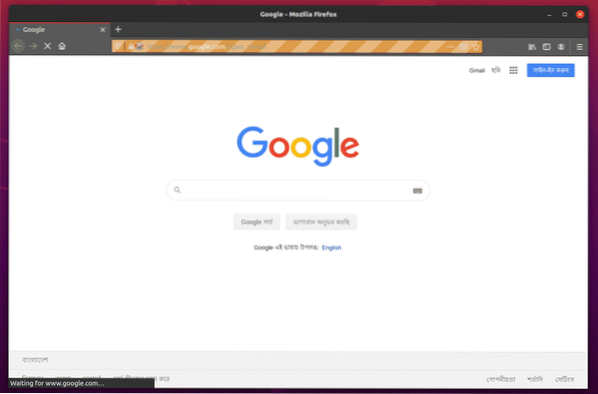
Уеб браузърът Firefox трябва автоматично да посещава Google.com и се затворете след 5 секунди. Ако това се случи, тогава драйверът на Selenium Firefox Gecko работи правилно.
Инсталиране на уеб уеб драйвер на Chrome
Уеб драйверът на Chrome ви позволява да контролирате или автоматизирате уеб браузъра Google Chrome с помощта на Selenium.
Трябва да изтеглите същата версия на уеб уеб драйвера на Chrome като тази на вашия уеб браузър Google Chrome.
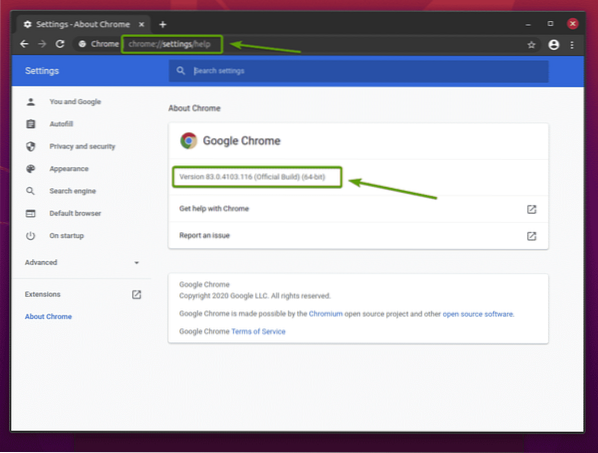
За да намерите номера на версията на вашия уеб браузър Google Chrome, посетете chrome: // settings / help в Google Chrome. Номерът на версията трябва да бъде в Всичко за Chrome раздел, както можете да видите на екранната снимка по-долу.
В моя случай номерът на версията е 83.0.4103.116. Първите три части от номера на версията (83.0.4103, в моя случай) трябва да съответства на първите три части от номера на версията на уеб уеб драйвера на Chrome.
За да изтеглите Chrome Web Driver, посетете официалната страница за изтегляне на Chrome Driver.
В Текущи версии секция Chrome Web Driver за най-актуалните версии на уеб браузъра Google Chrome ще бъде налице, както можете да видите на екранната снимка по-долу.
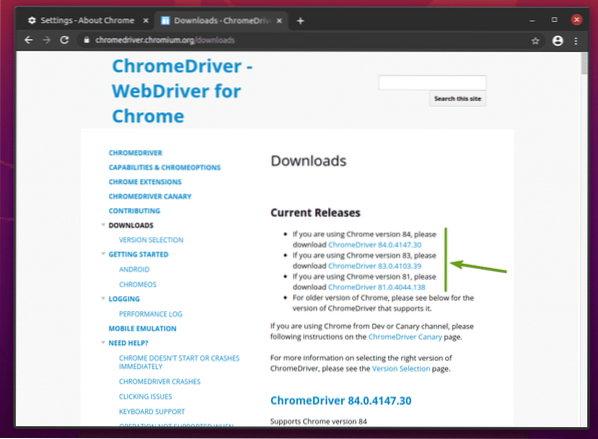
Ако версията на Google Chrome, която използвате, не е в Текущи версии раздел, превъртете малко надолу и трябва да намерите желаната версия.
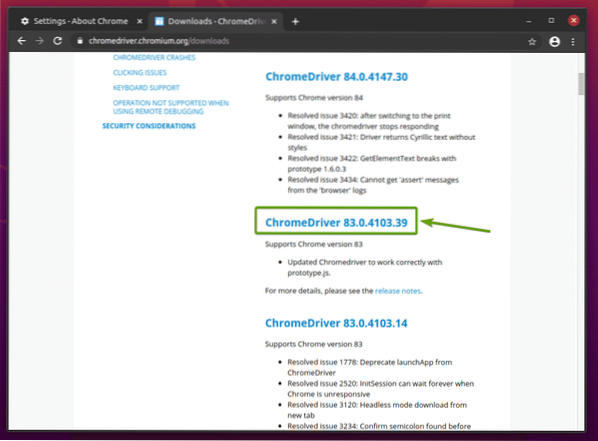
След като щракнете върху правилната версия на уеб уеб драйвера на Chrome, тя трябва да ви отведе на следващата страница. Кликнете върху chromedriver_linux64.цип връзка, както е отбелязано на екранната снимка по-долу.
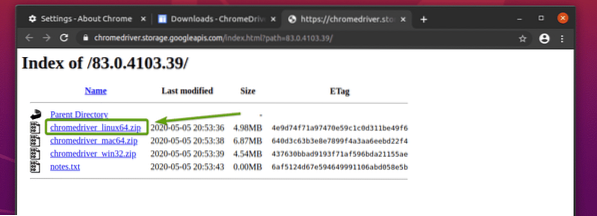
Вече трябва да се изтегли архивът за уеб уеб драйвер на Chrome.
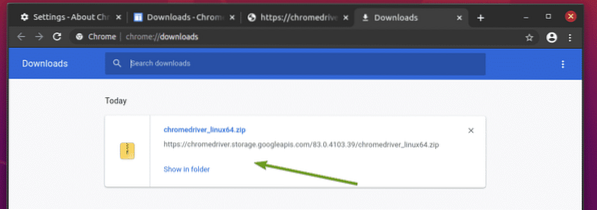
Архивът на уеб уеб драйвера на Chrome вече трябва да бъде изтеглен в ~ / Изтегляния директория.
Можете да извлечете chromedriver-linux64.цип архив от ~ / Изтегляния директория към шофьори / директория на вашия проект със следната команда:
$ unzip ~ / Downloads / chromedriver_linux64.zip -d драйвери /
След като архивът на Chrome Web Driver бъде извлечен, нов хромедривър двоичен файл трябва да бъде създаден в шофьори / директория на вашия проект, както можете да видите на екранната снимка по-долу.
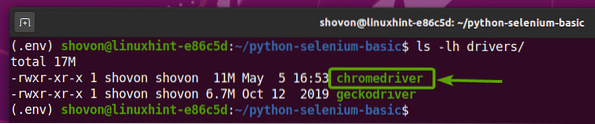
Тестване на уеб драйвер за Chrome на Selenium
В този раздел ще ви покажа как да настроите първия си скрипт на Selenium Python, за да тествате дали уеб уеб драйверът на Chrome работи.
Първо, създайте новия скрипт на Python ex02.py, и въведете следните редове кодове в скрипта.
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
от време внос сън
браузър = webdriver.Chrome (executable_path = "./ drivers / chromedriver ")
браузър.get ('http: // www.google.com ')
сън (5)
браузър.изход ()
След като приключите, запазете ex02.py Python скрипт.
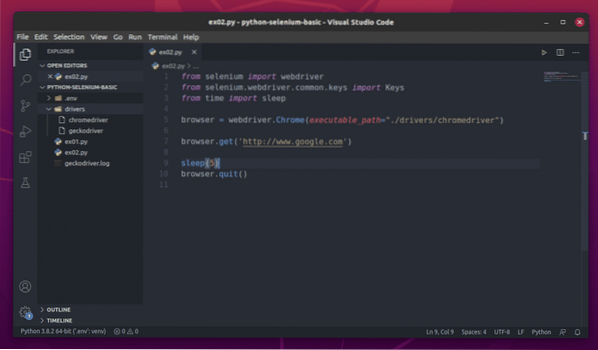
Ще обясня кода в следващ раздел на тази статия.
Следващият ред конфигурира Selenium да използва уеб драйвера на Chrome от шофьори / директория на вашия проект.

За да проверите дали уеб уеб драйверът на Chrome работи със Selenium, стартирайте ex02.py Python скрипт, както следва:
$ python3 ex01.py
Уеб браузърът Google Chrome трябва автоматично да посещава Google.com и се затворете след 5 секунди. Ако това се случи, тогава драйверът на Selenium Firefox Gecko работи правилно.
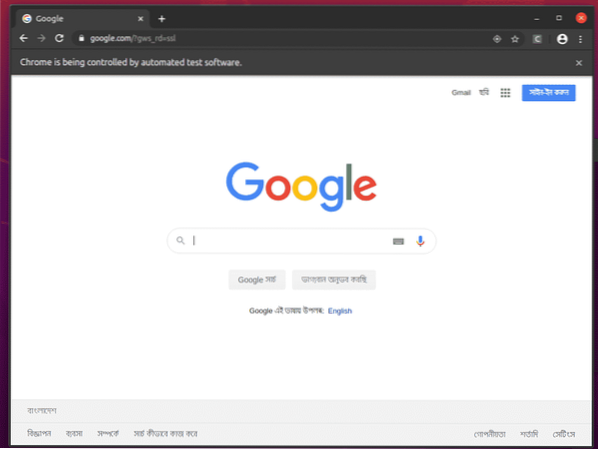
Основи на уеб изстъргване със селен
От сега нататък ще използвам уеб браузъра Firefox. Можете също да използвате Chrome, ако искате.
Основният скрипт на Selenium Python трябва да изглежда като скрипта, показан на екранната снимка по-долу.
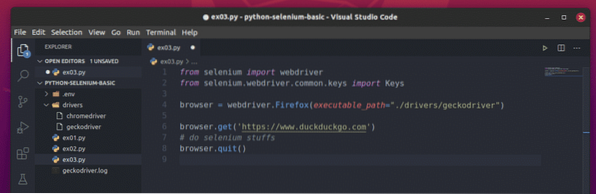
Първо, импортирайте селена уеб драйвер от селен модул.

След това импортирайте Ключове от селен.уеб драйвер.често срещани.ключове. Това ще ви помогне да изпратите натискания на клавишни клавиши към браузъра, който автоматизирате от Selenium.

Следващият ред създава a браузър обект за уеб браузъра Firefox с помощта на Firefox Gecko Driver (Webdriver). Можете да контролирате действията на браузъра Firefox, използвайки този обект.

За да заредите уебсайт или URL адрес (ще зареждам уебсайта https: // www.патешко патице.com), обадете се на получи () метод на браузър обект във вашия браузър Firefox.

Използвайки Selenium, можете да напишете тестовете си, да извършите бракуване в мрежата и накрая да затворите браузъра с помощта на изход () метод на браузър обект.

По-горе е основното оформление на скрипт на Selenium Python. Ще пишете тези редове във всичките си скриптове на Selenium Python.
Пример 1: Отпечатване на заглавието на уеб страница
Това ще бъде най-лесният пример, обсъждан с помощта на селен. В този пример ще отпечатаме заглавието на уеб страницата, която ще посещаваме.
Създайте новия файл ex04.py и въведете в него следните редове кодове.
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
браузър = webdriver.Firefox (изпълним_ път = "./ drivers / geckodriver ")
браузър.get ('https: // www.патешко патице.com ')
print ("Заглавие:% s"% браузър.заглавие)
браузър.изход ()
След като приключите, запазете файла.
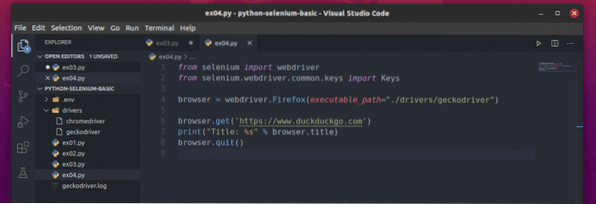
Ето, браузър.заглавие се използва за достъп до заглавието на посетената уеб страница и до печат () ще се използва за отпечатване на заглавието в конзолата.

След като стартирате ex04.py скрипт, той трябва:
1) Отворете Firefox
2) Заредете желаната от вас уеб страница
3) Вземете заглавието на страницата
4) Отпечатайте заглавието на конзолата
5) И накрая затворете браузъра
Както можете да видите, ex04.py script е отпечатал добре заглавието на уеб страницата в конзолата.
$ python3 ex04.py
Пример 2: Отпечатване на заглавия на множество уеб страници
Както в предишния пример, можете да използвате същия метод, за да отпечатате заглавието на множество уеб страници, като използвате цикъла Python.
За да разберете как работи това, създайте новия скрипт на Python ex05.py и въведете следните редове код в скрипта:
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
браузър = webdriver.Firefox (изпълним_ път = "./ drivers / geckodriver ")
urls = ['https: // www.патешко патице.com ',' https: // linuxhint.com ',' https: // yahoo.com ']
за url в urls:
браузър.получи (url)
print ("Заглавие:% s"% браузър.заглавие)
браузър.изход ()
След като приключите, запазете скрипта на Python ex05.py.
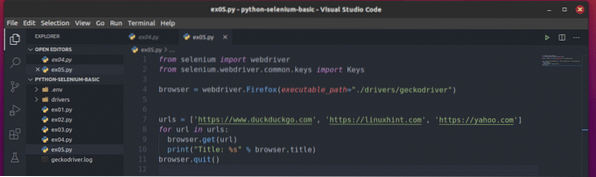
Ето, URL адреси list поддържа URL адреса на всяка уеб страница.

A за цикъл се използва за итерация през URL адреси елементи от списъка.
При всяка итерация Selenium казва на браузъра да посети url и вземете заглавието на уеб страницата. След като Selenium извлече заглавието на уеб страницата, тя се отпечатва в конзолата.

Стартирайте скрипта на Python ex05.py, и трябва да видите заглавието на всяка уеб страница в URL адреси списък.
$ python3 ex05.py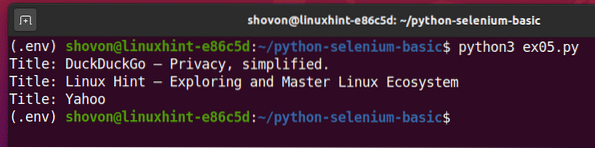
Това е пример за това как Selenium може да изпълнява една и съща задача с множество уеб страници или уебсайтове.
Пример 3: Извличане на данни от уеб страница
В този пример ще ви покажа основите на извличането на данни от уеб страници с помощта на Selenium. Това е известно и като изстъргване в мрежата.
Първо посетете Random.org връзка от Firefox. Страницата трябва да генерира произволен низ, както можете да видите на екранната снимка по-долу.
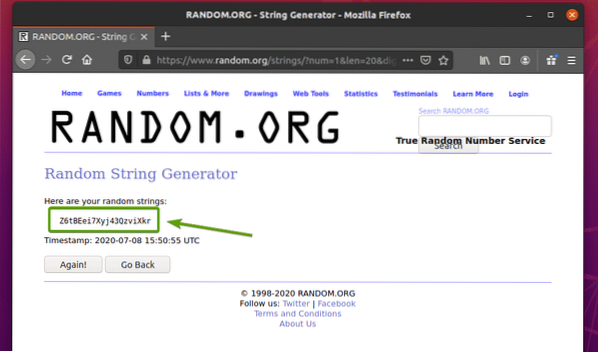
За да извлечете произволни данни от низове с помощта на Selenium, трябва също да знаете HTML представянето на данните.
За да видите как данните за случайни низове са представени в HTML, изберете данните за случаен низ и натиснете десния бутон на мишката (RMB) и кликнете върху Проверете елемента (Q), както е отбелязано на екранната снимка по-долу.
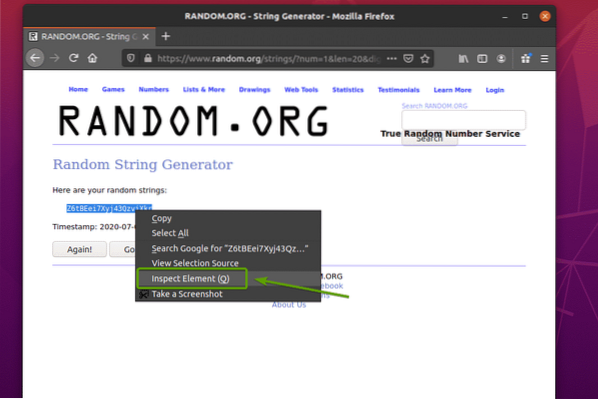
HTML представянето на данните трябва да се показва в Инспектор , както можете да видите на екранната снимка по-долу.
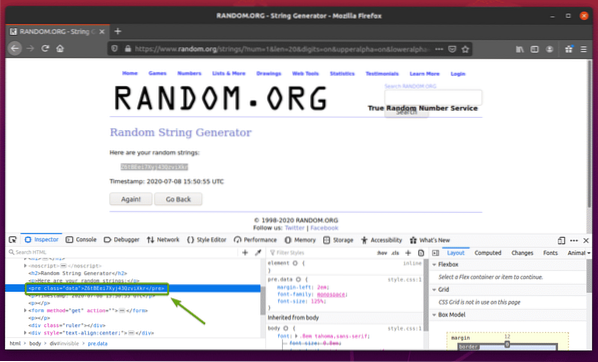
Можете също да кликнете върху Икона за проверка ( ) за да проверите данните от страницата.
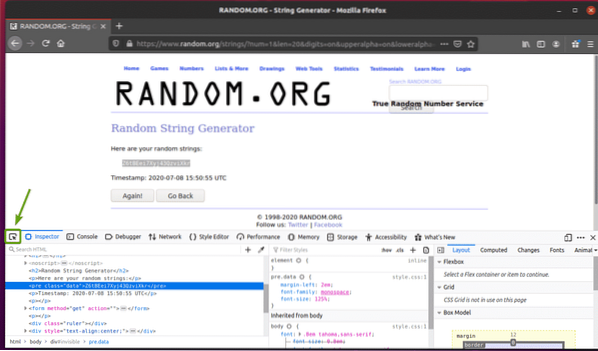
Кликнете върху иконата за проверка () и задръжте курсора на мишката върху произволните данни от низове, които искате да извлечете. HTML представянето на данните трябва да се показва както преди.
Както можете да видите, данните на произволен низ са обвити в HTML пред таг и съдържа класа данни.
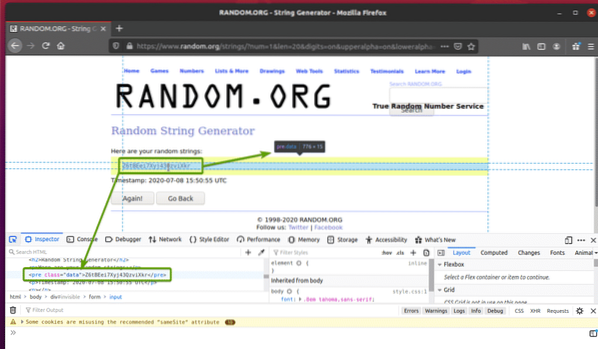
Сега, когато знаем HTML представяне на данните, които искаме да извлечем, ще създадем Python скрипт за извличане на данните с помощта на Selenium.
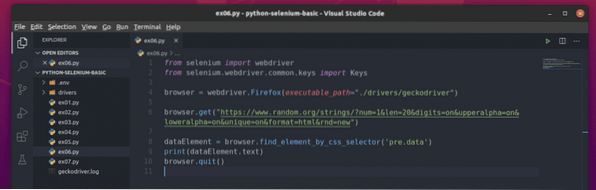
Създайте новия скрипт на Python ex06.py и въведете следните редове кодове в скрипта
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
браузър = webdriver.Firefox (изпълним_ път = "./ drivers / geckodriver ")
браузър.get ("https: // www.случайни.org / струни /?num = 1 & len = 20 & цифри
= on & upperalpha = on & loweralpha = on & unique = on & format = html & rnd = new ")
dataElement = браузър.find_element_by_css_selector ('предварително.данни')
print (dataElement.текст)
браузър.изход ()
След като приключите, запазете ex06.py Python скрипт.
Ето, браузър.получи () метод зарежда уеб страницата в браузъра Firefox.

The браузър.find_element_by_css_selector () метод търси HTML кода на страницата за конкретен елемент и го връща.
В този случай елементът би бил пред.данни, на пред етикет, който има името на класа данни.
По-долу пред.данни е съхранен в dataElement променлива.

След това скриптът отпечатва текстовото съдържание на избраното пред.данни елемент.

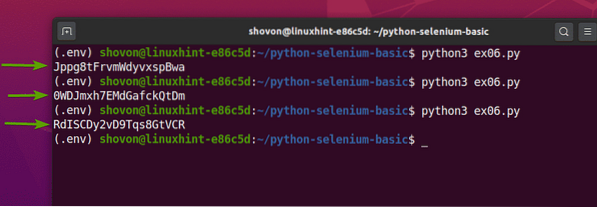
Ако стартирате ex06.py Python скрипт, той трябва да извлече данните на произволен низ от уеб страницата, както можете да видите на екранната снимка по-долу.
$ python3 ex06.py
Както можете да видите, всеки път, когато стартирам ex06.py Python скрипт, той извлича различни случайни низови данни от уеб страницата.
Пример 4: Извличане на списък с данни от уеб страница
Предишният пример ви показа как да извлечете единичен елемент от данни от уеб страница с помощта на Selenium. В този пример ще ви покажа как да използвате Selenium за извличане на списък с данни от уеб страница.
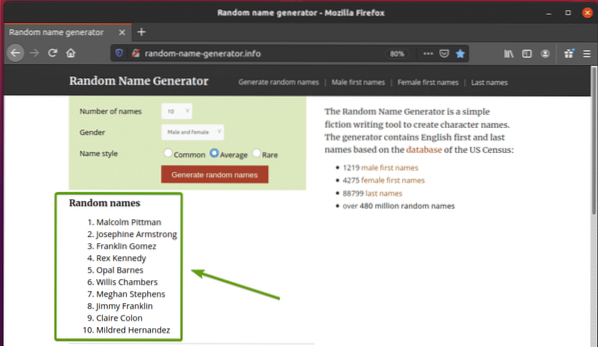
Първо посетете генератора на произволни имена.информация от вашия браузър Firefox. Този уебсайт ще генерира десет произволни имена всеки път, когато презаредите страницата, както можете да видите на екранната снимка по-долу. Нашата цел е да извлечем тези произволни имена с помощта на Selenium.
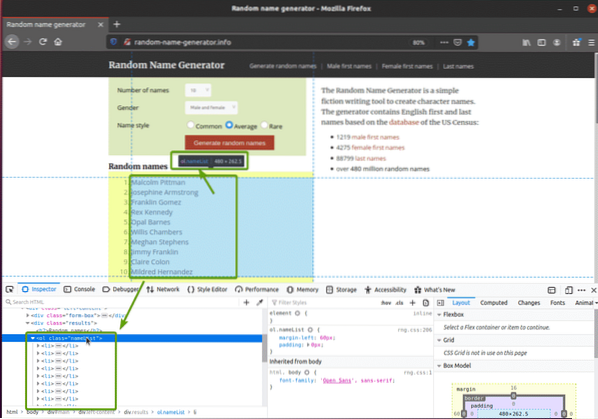
Ако разгледате по-внимателно списъка с имена, можете да видите, че това е подреден списък (ол таг). The ол tag включва и името на класа списък с имена. Всяко от произволните имена е представено като елемент от списък (ли етикет) в ол етикет.
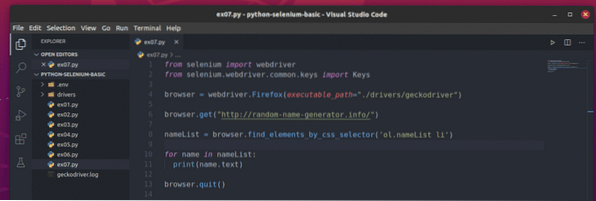
За да извлечете тези произволни имена, създайте новия скрипт на Python ex07.py и въведете следните редове кодове в скрипта.
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
браузър = webdriver.Firefox (изпълним_ път = "./ drivers / geckodriver ")
браузър.get ("http: // random-name-generator.информация / ")
nameList = браузър.find_elements_by_css_selector ('ol.nameList li ')
за име в списък с имена:
печат (име.текст)
браузър.изход ()
След като приключите, запазете ex07.py Python скрипт.
Ето, браузър.получи () метод зарежда уеб страницата на генератора на произволни имена в браузъра Firefox.

The браузър.find_elements_by_css_selector () метод използва CSS селектора ол.nameList li за да намерите всички ли елементи вътре в ол таг с име на класа списък с имена. Съхранил съм всички избрани ли елементи в списък с имена променлива.

A за цикъл се използва за итерация през списък с имена списък с ли елементи. Във всяка итерация съдържанието на ли елемент се отпечатва на конзолата.

Ако стартирате ex07.py Python скрипт, той ще извлече всички произволни имена от уеб страницата и ще ги отпечата на екрана, както можете да видите на екранната снимка по-долу.
$ python3 ex07.py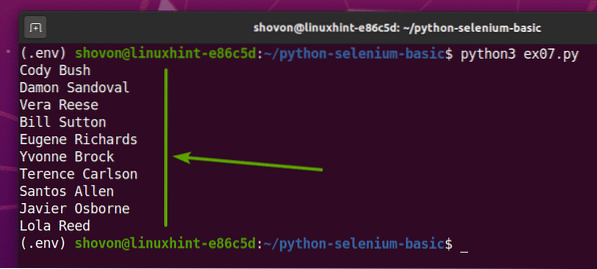
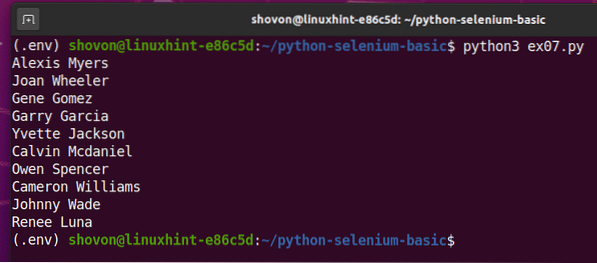
Ако стартирате скрипта за втори път, той трябва да върне нов списък с произволни потребителски имена, както можете да видите на екранната снимка по-долу.
Пример 5: Подаване на формуляр - Търсене в DuckDuckGo
Този пример е също толкова прост, колкото и първия пример. В този пример ще посетя търсачката DuckDuckGo и ще потърся термина селен hq използвайки селен.
Първо посетете DuckDuckGo Search Engine от уеб браузъра Firefox.
Ако проверите полето за въвеждане на търсене, то трябва да съдържа идентификатора search_form_input_homepage, както можете да видите на екранната снимка по-долу.
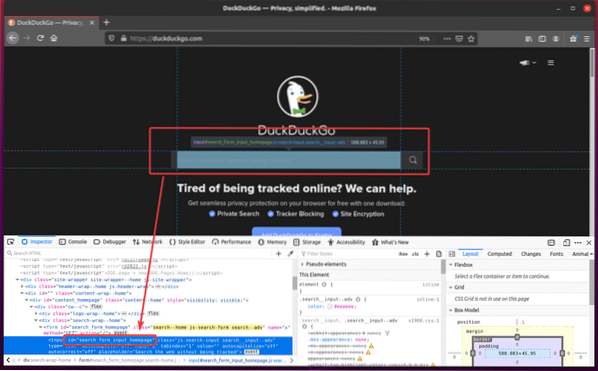
Сега създайте новия скрипт на Python ex08.py и въведете следните редове кодове в скрипта.
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
браузър = webdriver.Firefox (изпълним_ път = "./ drivers / geckodriver ")
браузър.get ("https: // duckduckgo.com / ")
searchInput = браузър.find_element_by_id ('search_form_input_homepage')
searchInput.send_keys ('селен hq' + клавиши.ENTER)
След като приключите, запазете ex08.py Python скрипт.
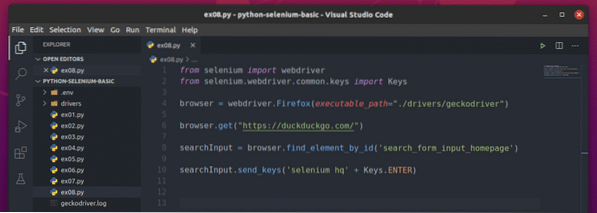
Ето, браузър.получи () метод зарежда началната страница на търсачката DuckDuckGo в уеб браузъра Firefox.

The браузър.find_element_by_id () метод избира входния елемент с идентификатора search_form_input_homepage и го съхранява в searchInput променлива.

The searchInput.send_keys () метод се използва за изпращане на данни за натискане на клавиши в полето за въвеждане. В този пример той изпраща низа селен hq, и клавишът Enter се натиска с помощта на Ключове.ENTER постоянна.
Веднага след като търсачката DuckDuckGo получи клавиша Enter, натиснете (Ключове.ENTER), той търси и показва резултата.

Стартирайте ex08.py Python скрипт, както следва:
$ python3 ex08.py
Както можете да видите, уеб браузърът Firefox посещава търсачката DuckDuckGo.

Той автоматично пише селен hq в текстовото поле за търсене.

Веднага след като браузърът получи клавиша Enter, натиснете (Ключове.ENTER), тя показва резултата от търсенето.
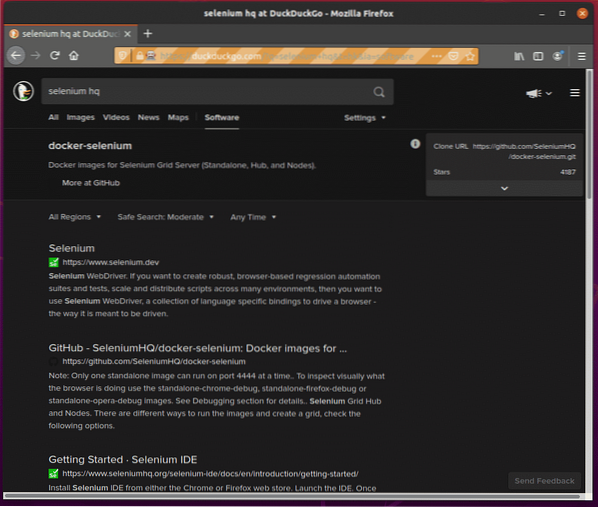
Пример 6: Подаване на формуляр в W3Schools.com
В пример 5 изпращането на формуляри за търсачки DuckDuckGo беше лесно. Всичко, което трябваше да направите, беше да натиснете клавиша Enter. Но това няма да е така при всички изпратени формуляри. В този пример ще ви покажа по-сложна обработка на формуляри.
Първо посетете страницата с HTML формуляри на W3Schools.com от уеб браузъра Firefox. След като страницата се зареди, трябва да видите примерен формуляр. Това е формулярът, който ще подадем в този пример.
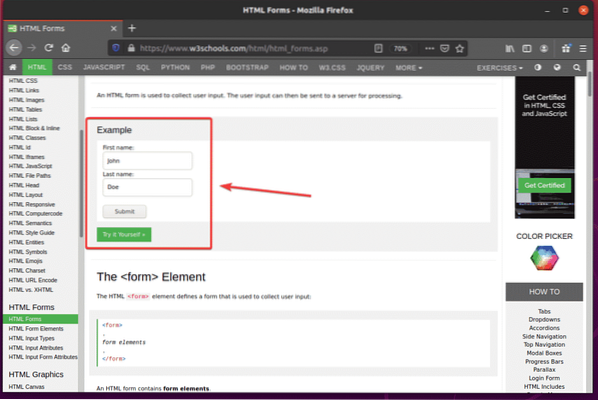
Ако проверите формуляра, Първо име полето за въвеждане трябва да съдържа идентификатора fname, на Фамилия полето за въвеждане трябва да съдържа идентификатора lname, и Бутон за изпращане трябва да има Тип Изпращане, както можете да видите на екранната снимка по-долу.
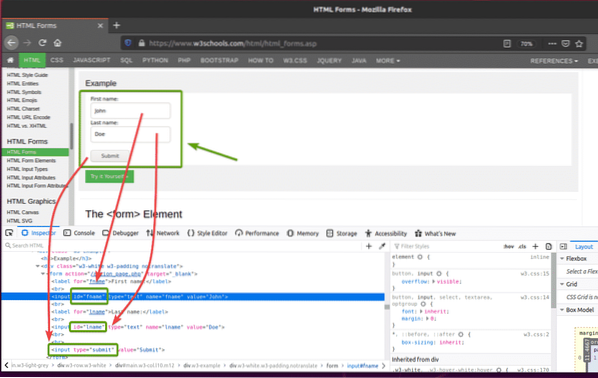
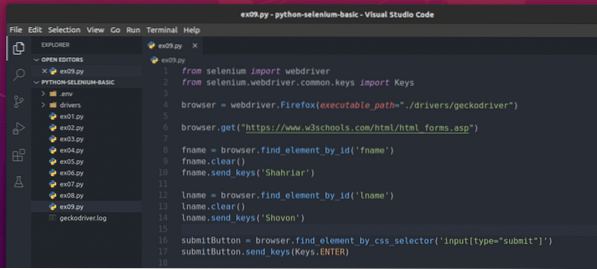
За да изпратите този формуляр с помощта на Selenium, създайте новия скрипт на Python ex09.py и въведете следните редове кодове в скрипта.
от webdriver за импортиране на селенот селен.уеб драйвер.често срещани.ключове за импортиране
браузър = webdriver.Firefox (изпълним_ път = "./ drivers / geckodriver ")
браузър.get ("https: // www.w3schools.com / html / html_forms.asp ")
fname = браузър.find_element_by_id ('fname')
fname.изчисти ()
fname.send_keys ('Shahriar')
lname = браузър.find_element_by_id ('lname')
lname.изчисти ()
lname.send_keys ('Shovon')
submitButton = браузър.find_element_by_css_selector ('input [type = "submit"]')
submitButton.send_keys (Клавиши.ENTER)
След като приключите, запазете ex09.py Python скрипт.
Ето, браузър.получи () метод отваря страницата с HTML формуляри W3schools в уеб браузъра Firefox.

The браузър.find_element_by_id () метод намира полетата за въвеждане по id fname и lname и ги съхранява в fname и lname променливи, съответно.


The fname.изчисти () и lname.изчисти () методи изчистват собственото име по подразбиране (Джон) fname стойност и фамилия (Doe) lname стойност от полетата за въвеждане.


The fname.send_keys () и lname.send_keys () тип методи Шахрияр и Шовон в Първо име и Фамилия полета за въвеждане, съответно.


The браузър.find_element_by_css_selector () метод избира Бутон за изпращане на формата и я съхранява в submitButton променлива.

The submitButton.send_keys () метод изпраща натискане на клавиша Enter (Ключове.ENTER) към Бутон за изпращане на формата. Това действие изпраща формуляра.

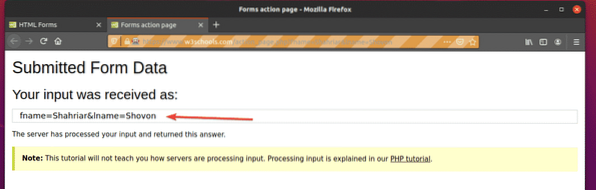
Стартирайте ex09.py Python скрипт, както следва:
$ python3 ex09.py
Както можете да видите, формулярът е изпратен автоматично с правилните данни.
Заключение
Тази статия трябва да ви помогне да започнете с тестване на браузър Selenium, уеб автоматизация и библиотеки за бракуване на уеб в Python 3. За повече информация вижте официалната документация за Selenium Python.


