Apache Solr
Apache Solr е една от най-популярните бази данни NoSQL, която може да се използва за съхраняване на данни и заявки в почти реално време. Базиран е на Apache Lucene и е написан на Java. Подобно на Elasticsearch, той поддържа заявки към бази данни чрез REST API. Това означава, че можем да използваме прости HTTP повиквания и да използваме HTTP методи като GET, POST, PUT, DELETE и т.н. за достъп до данни. Той също така предоставя опция за влизане под формата на XML или JSON чрез REST API.
В този урок ще изучим как да инсталираме Apache Solr на Ubuntu и да започнем да работим с него чрез основен набор от заявки към база данни.
Инсталиране на Java
За да инсталираме Solr на Ubuntu, първо трябва да инсталираме Java. Java може да не е инсталирана по подразбиране. Можем да го проверим с помощта на тази команда:
java -версияКогато изпълним тази команда, получаваме следния изход: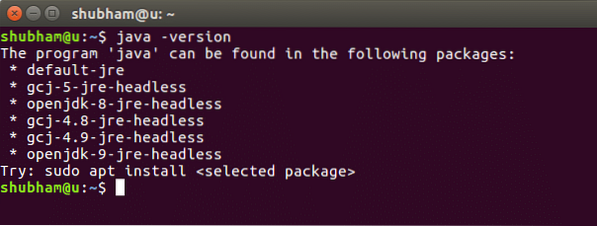
Сега ще инсталираме Java в нашата система. Използвайте тази команда, за да направите това:
sudo add-apt-repository ppa: webupd8team / javasudo apt-get update
sudo apt-get install oracle-java8-installer
След като тези команди са изпълнени, можем отново да проверим дали Java вече е инсталирана, като използваме същата команда.
Инсталиране на Apache Solr
Сега ще започнем с инсталирането на Apache Solr, което всъщност е само въпрос на няколко команди.
За да инсталираме Solr, трябва да знаем, че Solr не работи и не се изпълнява самостоятелно, а се нуждае от контейнер Java Servlet, за да стартира например контейнери Jetty или Tomcat Servlet. В този урок ще използваме сървър Tomcat, но използването на Jetty е доста подобно.
Хубавото на Ubuntu е, че той предлага три пакета, с които Solr може лесно да се инсталира и стартира. Те са:
- solr-общ
- solr-tomcat
- solr-jetty
Самоописателно е, че solr-common е необходим и за двата контейнера, докато solr-jetty е необходим за Jetty, а solr-tomcat е необходим само за Tomcat сървър. Тъй като вече сме инсталирали Java, можем да изтеглим пакета Solr с помощта на тази команда:
sudo wget http: // www-eu.апаш.org / dist / lucene / solr / 7.2.1 / solr-7.2.1.ципТъй като този пакет носи много пакети, включително Tomcat сървър, това може да отнеме няколко минути, за да изтеглите и инсталирате всичко. Изтеглете най-новата версия на Solr файлове от тук.
След като инсталацията приключи, можем да разархивираме файла, като използваме следната команда:
разархивирайте -q solr-7.2.1.ципСега променете директорията си в zip файла и ще видите следните файлове вътре:
Стартиране на Apache Solr Node
След като изтеглихме пакети Apache Solr на нашата машина, можем да направим повече като разработчик от интерфейс на възел, така че ще стартираме екземпляр на възел за Solr, където всъщност можем да правим колекции, да съхраняваме данни и да правим заявки за търсене.
Изпълнете следната команда, за да стартирате настройката на клъстера:
./ bin / solr start -e cloudЩе видим следния изход с тази команда: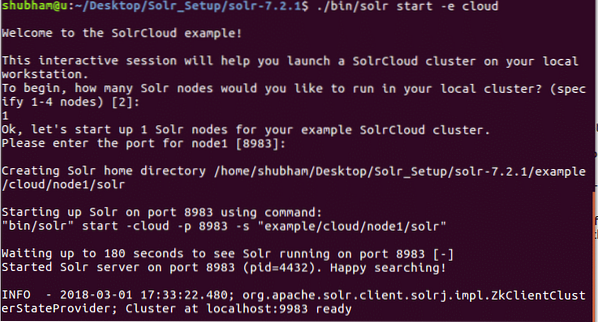
Ще бъдат зададени много въпроси, но ние ще настроим един възел Solr клъстер с всички конфигурации по подразбиране. Както е показано в последната стъпка, интерфейсът на възел Solr ще бъде достъпен на:
където 8983 е портът по подразбиране за възела. След като посетим горния URL, ще видим интерфейса на Node: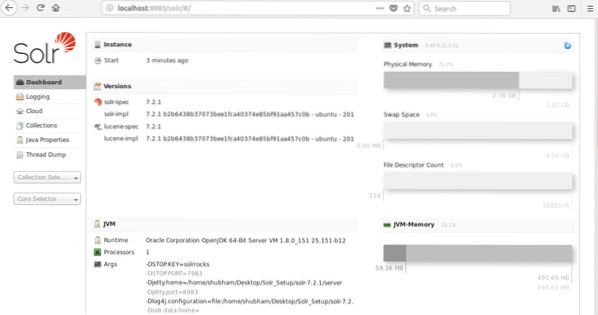
Използване на колекции в Solr
Сега, когато нашият интерфейс на възел е готов и работи, можем да създадем колекция с помощта на командата:
./ bin / solr create_collection -c linux_hint_collectionи ще видим следния изход:
Засега избягвайте предупрежденията. Вече можем да видим колекцията и в интерфейса на Node:
Сега можем да започнем с дефиниране на схема в Apache Solr, като изберем раздела за схемата: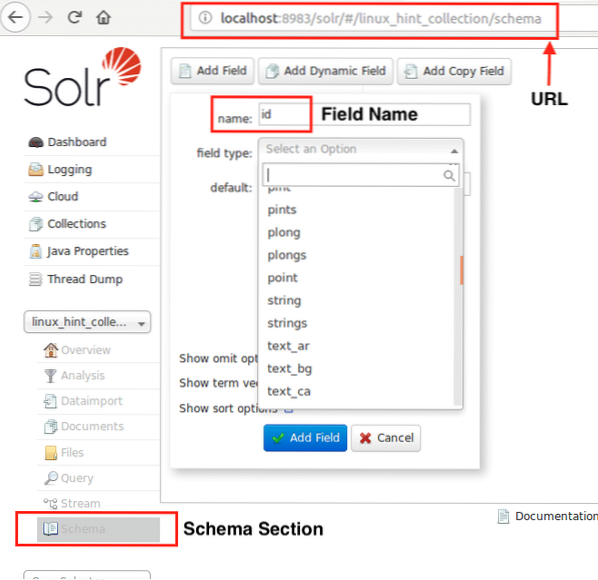
Вече можем да започнем да вмъкваме данни в нашите колекции. Нека вмъкнем JSON документ в нашата колекция тук:
curl -X POST -H 'Тип съдържание: application / json''http: // localhost: 8983 / solr / linux_hint_collection / update / json / docs' --data-binary '
"id": "iduye",
"name": "Shubham"
'
Ще видим успешен отговор срещу тази команда:
Като последна команда, нека видим как можем да ВЗЕМЕМ всички данни от колекцията Solr:
Ще видим следния изход:


