Филтрирайте списък от низове, като използвате друг списък
Този пример показва как данните в списък с низове могат да бъдат филтрирани, без да се използва какъвто и да е метод. Списъкът на низа се филтрира тук, като се използва друг списък. Тук се декларират две променливи от списъка с името списък1 и списък2. Стойностите на списък2 се филтрира чрез използване на стойностите на списък1. Скриптът ще съответства на първата дума от всяка стойност на списък2 със стойностите на списък1 и отпечатайте тези стойности, които не съществуват в списък1.
# Декларирайте две променливи от списъкаlist1 = ['Perl', 'PHP', 'Java', 'ASP']
list2 = ['JavaScript е скриптов език от страна на клиента',
„PHP е скриптов език от страна на сървъра“,
„Java е език за програмиране“,
„Bash е скриптов език“]
# Филтрирайте втория списък въз основа на първия списък
filter_data = [x за x в list2 if
всички (y не в x за y в списък1)]
# Отпечатайте данните от списъка преди филтър и след филтър
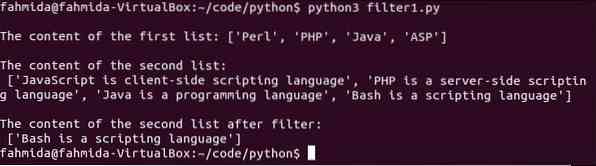
print ("Съдържанието на първия списък:", list1)
print ("Съдържанието на втория списък:", list2)
print ("Съдържанието на втория списък след филтър:", filter_data)
Изход:
Стартирайте скрипта. Тук, списък1 не съдържа думата "Баш'. Резултатът ще съдържа само една стойност от списък2 това е 'Bash е скриптов език ".
Филтрирайте списък от низове, като използвате друг списък и персонализирана функция
Този пример показва как списък от низове може да бъде филтриран с помощта на друг списък и персонализираната функция на филтъра. Скриптът съдържа две променливи на списъка, наречени list1 и list2. Функцията за персонализиран филтър ще открие общите стойности на двете променливи от списъка.
# Декларирайте две променливи от списъкаlist1 = ['90', '67', '34', '55', '12', '87', '32']
list2 = ['9', '90', '38', '45', '12', '20']
# Декларирайте функция за филтриране на данни от първия списък
def филтър (list1, list2):
върнете [n за n в list1, ако
всеки (m в n за m в списък2)]
# Отпечатайте данните от списъка преди филтъра и след филтъра
print ("Съдържанието на list1:", list1)
print ("Съдържанието на list2:", list2)
print ("Данните след филтъра", Filter (list1, list2))
Изход:
Стартирайте скрипта. В двете променливи от списъка съществуват 90 и 12 стойности. Следният изход ще бъде генериран след стартиране на скрипта.

Филтрирайте списък от низове, като използвате регулярен израз
Списъкът се филтрира с помощта на всичко() и всеки () методи в предишните два примера. В този пример се използва регулярен израз за филтриране на данните от списък. Регулярният израз е модел, по който всички данни могат да бъдат търсени или съпоставени. ти си модул се използва в python за прилагане на регулярен израз в скрипта. Тук се декларира списък с тематични кодове. Регулярният израз се използва за филтриране на тези кодове на теми, които започват с думата, 'CSE'. '^'символът се използва в шаблони на регулярни изрази за търсене в началото на текста.
# Импортиране на модул re за използване на регулярен изразвнос re
# Декларирайте, че списъкът съдържа тематичен код
sublist = ['CSE-407', 'PHY-101', 'CSE-101', 'ENG-102', 'MAT-202']
# Декларирайте функцията за филтриране
дефилтриращ филтър (даталист):
# Търсене на данни въз основа на регулярния израз в списъка
return [val за val в даталист
ако повторно.търсене (r '^ CSE', val)]
# Отпечатайте данните на филтъра
печат (Филтър (подлист))
Изход:
Стартирайте скрипта. подлист променливата съдържа две стойности, които започват с 'CSE'. След стартиране на скрипта ще се появи следният изход.

Филтрирайте списък с низове, използвайки lamda израз
Този пример показва използването на ламда израз за филтриране на данни от списък с низове. Тук е посочена променлива на списъка дума за търсене се използва за филтриране на съдържание от текстова променлива с име текст. Съдържанието на текста се преобразува в списък с име, text_word въз основа на пространството чрез използване разделяне () метод. ламда изразът ще пропусне тези стойности от text_word които съществуват в дума за търсене и съхранявайте филтрираните стойности в променлива чрез добавяне на интервал.
# Декларирайте списък, който съдържа думата за търсенеsearch_word = ["Преподавам", "Код", "Програмиране", "Блог"]
# Определете текста, в който думата от списъка ще търси
text = "Научете Python програмиране от Linux Hint Blog"
# Разделете текста на базата на интервал и съхранявайте думите в списък
text_word = текст.разделяне ()
# Използвайки ламбда израз, филтрирайте данните
filter_text = ".join ((филтър (lambda val: val not i
n search_word, text_word)))
# Отпечатайте текст преди филтриране и след филтриране
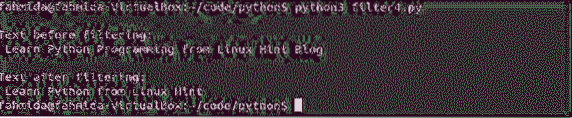
print ("\ nТекст преди филтриране: \ n", текст)
print ("Текст след филтриране: \ n", filter_text)
Изход:
Стартирайте скрипта. След стартиране на скрипта ще се появи следният изход.
Филтрирайте списък от низове с помощта на метода filter ()
филтър () метод приема два параметъра. Първият параметър взема име на функция или Нито един а вторият параметър приема името на променливата от списъка като стойности. филтър () метод съхранява тези данни от списъка, ако връща true, в противен случай изхвърля данните. Тук, Нито един се дава като първата стойност на параметъра. Всички стойности без невярно ще бъдат извлечени от списъка като филтрирани данни.
# Декларирайте списък с микс данниlistData = ['Hello', 200, 1, 'World', False, True, '0']
# Метод за извикване на филтър () с None и списък
filteredData = филтър (Няма, listData)
# Отпечатайте списъка след филтриране на данните
print ('Списъкът след филтриране:')
за вал във филтрирани данни:
печат (вал)
Изход:
Стартирайте скрипта. Списъкът съдържа само една фалшива стойност, която ще бъде пропусната във филтрираните данни. След стартиране на скрипта ще се появи следният изход.

Заключение:
Филтрирането е полезно, когато трябва да търсите и извличате определени стойности от списък. Надявам се, горните примери ще помогнат на читателите да разберат начините за филтриране на данни от списък с низове.


