Тази статия ви показва как да намерите дубликати в данни и да премахнете дубликатите с помощта на функциите на Pandas Python.
В тази статия взехме набор от данни за населението на различни щати в САЩ, който е достъпен в .CSV файлов формат. Ще прочетем .csv файл, за да покаже оригиналното съдържание на този файл, както следва:
импортирайте панди като pddf_state = pd.read_csv ("C: / Потребители / DELL / Работен плот / население_ds.csv ")
печат (df_state)
На следващата екранна снимка можете да видите дублираното съдържание на този файл:
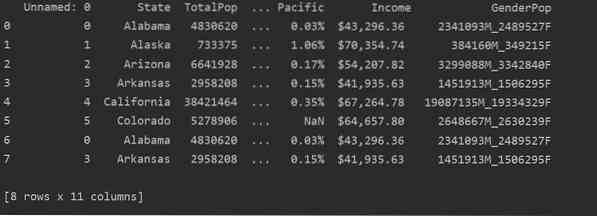
Идентифициране на дубликати в Pandas Python
Необходимо е да се определи дали данните, които използвате, имат дублирани редове. За да проверите за дублиране на данни, можете да използвате някой от методите, описани в следващите раздели.
Метод 1:
Прочетете csv файла и го предайте в рамката за данни. След това идентифицирайте дублиращите се редове с помощта на дублиран () функция. И накрая, използвайте инструкцията за печат, за да покажете дублиращите се редове.
импортирайте панди като pddf_state = pd.read_csv ("C: / Потребители / DELL / Работен плот / население_ds.csv ")
Dup_Rows = df_state [df_state.дублиран ()]
print ("\ n \ nПовторени редове: \ n ".формат (Dup_Rows))
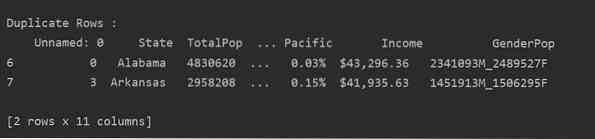
Метод 2:
Използвайки този метод, is_duplicated колоната ще бъде добавена в края на таблицата и маркирана като „True“ в случай на дублирани редове.
импортирайте панди като pddf_state = pd.read_csv ("C: / Потребители / DELL / Работен плот / население_ds.csv ")
df_state ["is_duplicate"] = df_state.дублиран ()
print ("\ n ".формат (df_state))
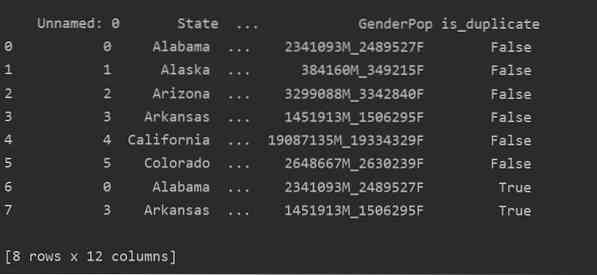
Отпадане на дубликати в Pandas Python
Дублираните редове могат да бъдат премахнати от вашата рамка с данни, като се използва следният синтаксис:
drop_duplicates (subset = ", keep =", inplace = False)
Горните три параметъра не са задължителни и са обяснени по-подробно по-долу:
пазя: този параметър има три различни стойности: First, Last и False. Първата стойност запазва първата поява и премахва последващи дубликати, последната стойност запазва само последната поява и премахва всички предишни дубликати, а стойността False премахва всички дублирани редове.
подмножество: етикет, използван за идентифициране на дублираните редове
на място: съдържа две условия: True и False. Този параметър ще премахне дублираните редове, ако е зададен на True.
Премахване на дубликати, запазвайки само първата поява
Когато използвате „keep = first“, ще се запази само появата на първия ред, а всички останали дубликати ще бъдат премахнати.
Пример
В този пример ще бъде запазен само първият ред, а останалите дубликати ще бъдат изтрити:
импортирайте панди като pddf_state = pd.read_csv ("C: / Потребители / DELL / Работен плот / население_ds.csv ")
Dup_Rows = df_state [df_state.дублиран ()]
print ("\ n \ nПовторени редове: \ n ".формат (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (keep = 'first')
print ('\ n \ nРезултат на DataFrame след премахване на дубликат: \ n', DF_RM_DUP.глава (n = 5))
В следващата екранна снимка запазеният първи ред е маркиран в червено, а останалите дублирания са премахнати:
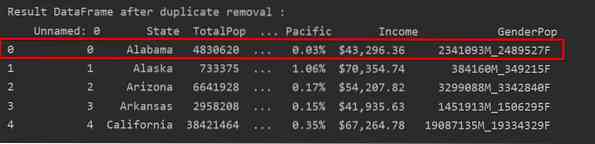
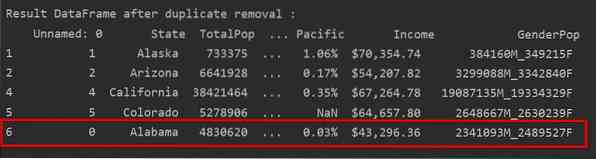
Премахване на дубликати, запазвайки само последната поява
Когато използвате „keep = last“, всички дублирани редове с изключение на последното ще бъдат премахнати.
Пример
В следващия пример всички дублирани редове се премахват с изключение само на последното появяване.
импортирайте панди като pddf_state = pd.read_csv ("C: / Потребители / DELL / Работен плот / население_ds.csv ")
Dup_Rows = df_state [df_state.дублиран ()]
print ("\ n \ nПовторени редове: \ n ".формат (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (keep = 'last')
print ('\ n \ nРезултат на DataFrame след премахване на дубликат: \ n', DF_RM_DUP.глава (n = 5))
В следващото изображение дубликатите се премахват и се запазва само последното появяване на ред:
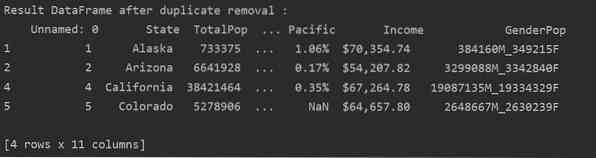
Премахнете всички дублирани редове
За да премахнете всички дублиращи се редове от таблица, задайте „keep = False“, както следва:
импортирайте панди като pddf_state = pd.read_csv ("C: / Потребители / DELL / Работен плот / население_ds.csv ")
Dup_Rows = df_state [df_state.дублиран ()]
print ("\ n \ nПовторени редове: \ n ".формат (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (keep = False)
print ('\ n \ nРезултат на DataFrame след премахване на дубликат: \ n', DF_RM_DUP.глава (n = 5))
Както можете да видите на следващото изображение, всички дубликати се премахват от рамката с данни:
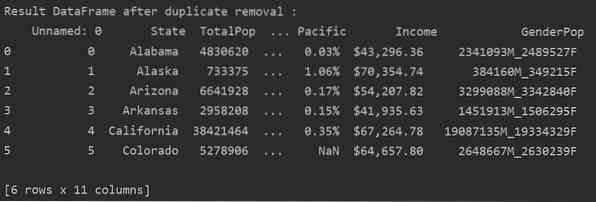
Премахване на сродни дубликати от посочена колона
По подразбиране функцията проверява за всички дублирани редове от всички колони в дадената рамка с данни. Но можете също да посочите името на колоната, като използвате параметъра на подмножеството.
Пример
В следващия пример всички свързани дубликати се премахват от колоната „Държави“.
импортирайте панди като pddf_state = pd.read_csv ("C: / Потребители / DELL / Работен плот / население_ds.csv ")
Dup_Rows = df_state [df_state.дублиран ()]
print ("\ n \ nДублиращи редове: \ n ".формат (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (subset = 'State')
print ('\ n \ nРезултат на DataFrame след премахване на дубликат: \ n', DF_RM_DUP.глава (n = 6))
Заключение
Тази статия ви показа как да премахнете дублирани редове от рамка за данни с помощта на drop_duplicates () функция в Pandas Python. Можете също да изчистите данните си от дублиране или излишък, използвайки тази функция. Статията също така ви показа как да идентифицирате дубликати във вашата рамка с данни.


