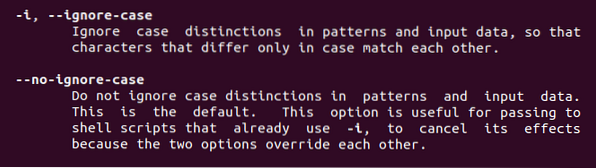
От тази команда ще открием две характеристики, описани по-горе. -Искам да игнорирам случая, където и да се използва тази ключова дума, пристрастяването към случая се премахва.
Предпоставка
За да постигнем постигането на функционалността на тази функция в операционната система Linux, трябва да имаме инсталирана ОС Linux. След конфигуриране ще предоставите необходимата потребителска информация, с помощта на която потребителят ще бъде влязъл в системата. Освен това, когато са предоставени потребителското име и паролата, потребителят ще има достъп до всички вградени функции на операционната система. И накрая, след като се осъществи достъп до работния плот, от вас се изисква достъп до терминала, тъй като на него трябва да се изпълняват команди.
Пример 1:
В този пример ще видим как grep помага при избягването на чувствителността към регистъра. Помислете за файл с име11.текст. Файлът съдържа следните данни в него; както можете да видите думата манго е написана по различни начини, някои думи са с главни букви, а други са с малки букви. С помощта на командата cat ще покажем данните на файла.
$ cat файлове11.текст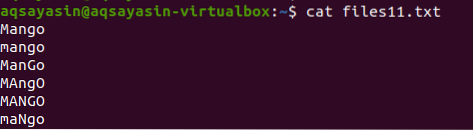
След като командата се използва за показване на данните, може да се забележи, че се показва единствената дума, която съвпада с буквата, присъстваща в командата. Всички букви са с малки букви.
$ grep манго файлове 11.текст
Сега, за да разберем концепцията за нечувствителност към регистъра, ще използваме “-I” в командата, за да се справим с чувствителността към регистъра, като предоставим всички данни, присъстващи във файла, съответстващи на низа, присъстващ в командата.
$ grep -И манго файлове11.текст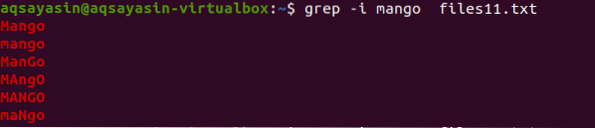
От изхода ще разберете, че всички данни, които съответстват на думата „манго“, се показват или с някои думи, написани с главни букви, а някои са с малки букви.
Пример 2
Този пример прилича на първия, разликата е, че се получава само една дума. Тази команда помага за получаването на целия низ чрез съвпадение с думата, предоставена в командата. Нека имаме файл filea.текст. като пример искаме да извлечем запис според даденото съвпадение.
$ cat filea.текст
Сега приложете същата команда, за да игнорирате случая и да изобразите изхода. Техническата дума се показва чрез изключване на регистъра, за да стане чувствителен към малки и големи букви.

Пример 3
Друг метод за използване на grep за игнориране на случай е първо да се въведе име на файл и по-късно да се приложи командата -I с grep след „|“ оператор. Cat се използва заедно с „|“. Нека имаме файл с име file24.текст. като пример.
$ Cat файл24.txt | grep -I “Aqsa”Тази команда ще извлече думата "Aqsa" както в главни, така и в малки букви.

Пример 4
Преминаване към друг пример. Тук ще покажем данните на файла, съдържащ думата „моя“. Тук търсенето се извършва чрез въвеждане на директория, като по този начин командата ще сортира думата във всички файлове с разширение .txt в системата.
$ grep -I my / home / aqsayasin / *.текст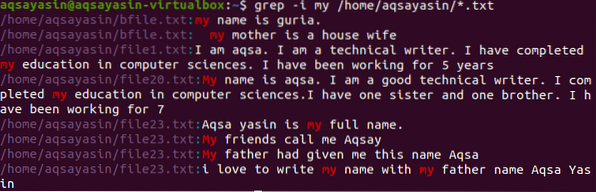
Горното изображение показва изхода, получен от командата. „Моята“ дума е подчертана, това е и в двата случая. Някои файлове го съдържат с малки букви, докато други го имат с главни. Адресът на файловете и имената на файловете също се показват.
Пример 5
Този пример може да се приложи към директорията, съдържаща всички файлове в нея. Ще бъдат приложени ограничения за показване на конкретния резултат, който съвпада с думата, която сме дефинирали в командата. Думата „is“ се използва за търсене във всички файлове в системата.
$ grep -I is / home / aqsayasin / file *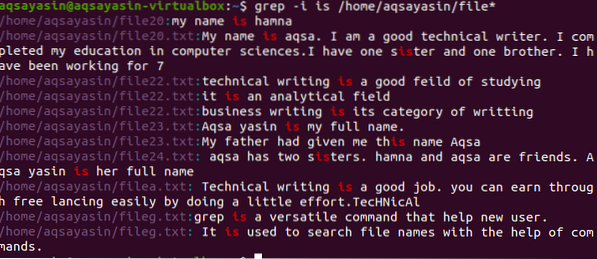
Изходът показва цели низове, съдържащи съответната дума в него. Както „е“ се пише отделно или се комбинира в друга дума i.д. сестра.
Пример 6
Следващата команда показва как -iw работи заедно в командата. Освен това търсенето става чрез две думи в един файл. Обратната наклонена черта и „|“ се използват за описание на две думи във файл, докато -w се използва за точното съвпадение на съответната дума във файла.
$ grep -iw 'hamna \ | къща' файл21.текст$ grep 'hamn \ | house' файл21.текст

-Ще пренебрегна чувствителността към малките и малки букви. В горния пример можем да видим, че наличието на -w с -I, позволява къща в първата команда да не се разглежда, защото -w позволява точното съвпадение. Във втората команда премахнахме и двете -iw, следователно и двете думи се показват след съвпадение в низ.
Пример 7
Търси се повече от една дума чрез прилагане на различен метод. И двете думи се търсят от един и същ файл, тези думи са „работа“ и „печелете“. Печелете се извлича от думата учене, а също така имайте предвид, че всяка дума е отделена от ключовата дума -e.
$ grep -I -e работа -e печеля filea.текст
Горното изображение показва всички низове в абзац относно думите, присъстващи в командата. Подобно на горните примери, -Игнорирах всякаква дискриминация на думите работа и печеля.
Пример 8
В този пример търсене на две думи, присъстващи във всички файлове на .txt разширение. Тези две думи са разделени с -e, тъй като -e е правилният начин за разделяне на две думи. Получените резултати ще имат и двете думи, показани във всички файлове с разширение на текста. Получава се и се показва целият адрес на файла. -Ще игнорирам чувствителността на малки и големи букви и ще покажа и двете думи, присъстващи във всички файлове.
$ grep -I -e работа -e печеля / home / aqsayasin / *.текст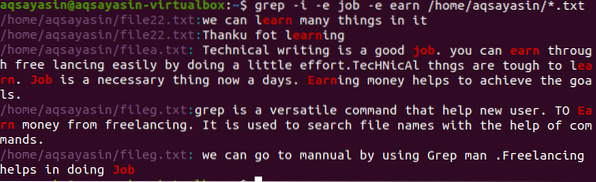
Заключение
В това ръководство използвахме най-простия пример, за да разгледаме концепцията за чувствителност към регистъра. Постарахме се по най-добрия начин да преминем през всеки аспект, за да подобрим знанията относно grep.


