Световната мрежа е всеобхватният и краен източник на всички данни, които съществуват. Бързото развитие, което Интернет наблюдава през последните три десетилетия, е безпрецедентно. В резултат на това мрежата се монтира със стотици терабайта данни всеки изминал ден.
Всички тези данни имат някаква стойност за определен човек. Например историята ви на сърфиране има значение за приложенията в социалните медии, тъй като те я използват, за да персонализират рекламите, които ви показват. И за тези данни има голяма конкуренция; няколко MB повече от някои данни могат да дадат на бизнеса значително предимство пред конкуренцията.
Извличане на данни с Python
За да помогнем на тези от вас, които са нови в изчистването на данни, подготвихме това ръководство, в което ще покажем как да изстъргвате данни от мрежата с помощта на библиотека Python и Beautiful супа.
Предполагаме, че вече имате междинно познаване на Python и HTML, тъй като ще работите и с двете, следвайки инструкциите в това ръководство.
Бъдете внимателни на кои сайтове изпробвате новооткритите си умения за извличане на данни, тъй като много сайтове смятат това за натрапчиво и знаят, че може да има последици.
Инсталиране и подготовка на библиотеките
Сега ще използваме две библиотеки, които ще използваме: библиотеката за заявки на python за зареждане на съдържание от уеб страници и библиотеката Beautiful Soup за действителното битово изстъргване на процеса. Има алтернативи на BeautifulSoup, имайте предвид, и ако сте запознати с някое от следните, не се колебайте да ги използвате вместо тях: Scrappy, Mechanize, Selenium, Portia, kimono и ParseHub.
Библиотеката на заявките може да бъде изтеглена и инсталирана с командата pip, както е показано по-долу:
# pip3 заявки за инсталиране
Библиотеката на заявките трябва да бъде инсталирана на вашето устройство. По същия начин изтеглете и BeautifulSoup:
# pip3 инсталирайте beautifulsoup4
С това нашите библиотеки са готови за някои действия.
Както бе споменато по-горе, библиотеката на заявките няма много полза, освен извличането на съдържанието от уеб страниците. Библиотеката BeautifulSoup и библиотеките за заявки имат място във всеки скрипт, който ще напишете, и те трябва да бъдат импортирани преди всяка, както следва:
$ заявки за внос$ от bs4 импортирайте BeautifulSoup като bs
Това добавя исканата ключова дума към пространството на имената, като сигнализира на Python значението на ключовата дума винаги, когато бъде поискано нейното използване. Същото се случва и с ключовата дума bs, въпреки че тук имаме предимството да присвоим по-проста ключова дума за BeautifulSoup.
уеб страница = заявки.получи (URL)Кодът по-горе извлича URL адреса на уеб страницата и създава директен низ от него, като го съхранява в променлива.
$ webcontent = уеб страница.съдържаниеКомандата по-горе копира съдържанието на уеб страницата и ги присвоява на променливото уеб съдържание.
С това приключихме с библиотеката със заявки. Остава само да промените опциите на библиотеката на заявките в BeautifulSoup.
$ htmlcontent = bs (webcontent, “html.парсер “)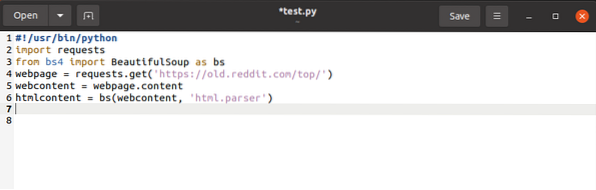
Това анализира обекта на заявката и го превръща в четливи HTML обекти.
С всичко, за което се погрижихме, можем да преминем към действителното битово стържене.
Уеб изстъргване с Python и BeautifulSoup
Нека да продължим напред и да видим как можем да изстъргваме HTML обекти с данни с BeautifulSoup.
За да илюстрираме пример, докато обясняваме нещата, ще работим с този html фрагмент:
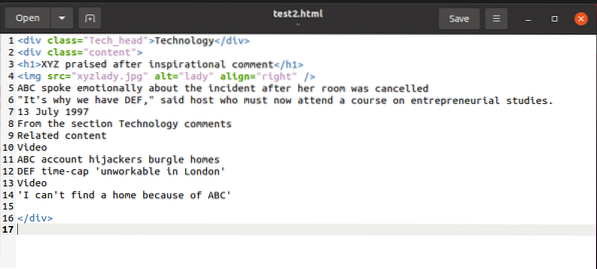
Можем да осъществим достъп до съдържанието на този фрагмент с BeautifulSoup и да го използваме в променливата на HTML съдържанието, както е описано по-долу:
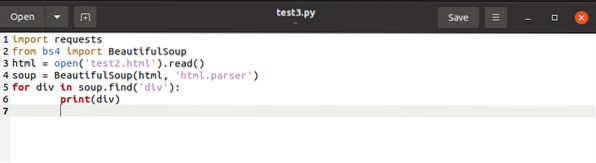
Кодът по-горе търси всякакви имена
За да запазите едновременно имената на етикетите
към списък, бихме издали окончателния код, както е описано по-долу: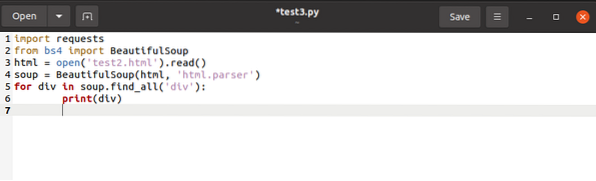
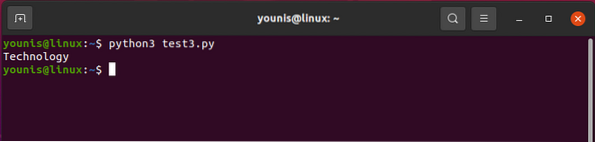
Изходът трябва да се върне по следния начин:
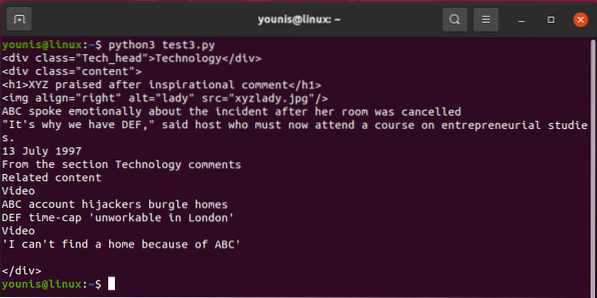
За да призовем един от
Сега нека видим как да изберем
етикети, поддържащи в перспектива техните характеристики. За да отделите a , ще ни трябва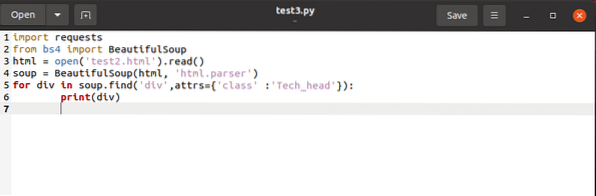
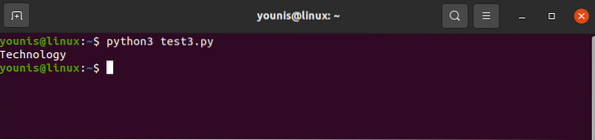
за div в супа.find_all ('div', attrs = 'class' = 'Tech_head'):
Това извлича
етикет.Ще получите:
Технология
Всички без етикети.
И накрая, ще разгледаме как да изберем стойността на атрибута в таг. Кодът трябва да има този маркер:
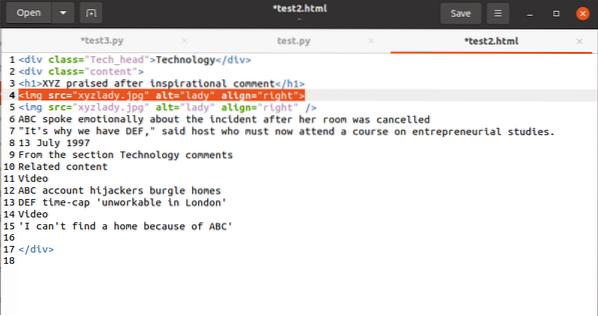

За да оперирате стойността, свързана с атрибута src, ще използвате следното:
htmlcontent.намиране („img“) [„src“]И изходът ще се окаже като:
"images_4 / a-beginners-guide-to-web-scraping-with-python-and-beautiful-супа.jpg "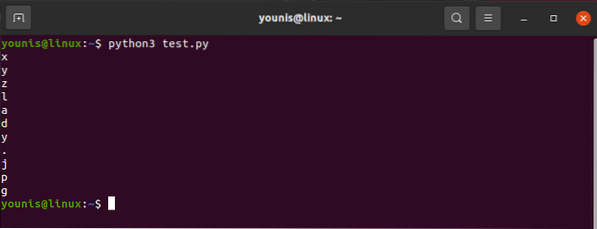
О, момче, това със сигурност е много работа!
Ако смятате, че познаването ви с python или HTML е недостатъчно или ако просто сте затрупани с изстъргването в мрежата, не се притеснявайте.
Ако сте бизнес, който трябва редовно да придобива определен тип данни, но не можете сами да изчиствате мрежата, има начини да заобиколите този проблем. Но знайте, че това ще ви струва малко пари. Можете да намерите някой, който да извърши изстъргването вместо вас, или можете да получите първокласната услуга за данни от уебсайтове като Google и Twitter, за да споделите данните с вас. Те споделят части от данните си чрез използване на API, но тези API повиквания са ограничени на ден. Освен това уебсайтове като тези могат да бъдат много защитни за своите данни. Обикновено много такива сайтове изобщо не споделят никакви свои данни.
Финални мисли
Преди да приключим, позволете ми да ви кажа на глас, ако това вече не се разбира от само себе си; командите find (), find_all () са най-добрите ви приятели, когато излизате от стърженето с BeautifulSoup. Въпреки че има много повече неща, които да покриете, за да изтриете основните данни с Python, това ръководство трябва да е достатъчно за тези от вас, които тепърва започват.


