- 1 за вярно или
- 0 за false
Ключовото значение на логистичната регресия:
- Независимите променливи не трябва да са мултиколинеарност; ако има някаква връзка, то тя трябва да е много малко.
- Наборът от данни за логистичната регресия трябва да бъде достатъчно голям, за да се получат по-добри резултати.
- В набора от данни трябва да има само тези атрибути, което има някакво значение.
- Независимите променливи трябва да съответстват на log шансове.
За изграждане на модела на логистична регресия, ние използваме scikit-learn библиотека. Процесът на логистична регресия в python е даден по-долу:
- Импортирайте всички необходими пакети за логистична регресия и други библиотеки.
- Качете набора от данни.
- Разберете независимите променливи от набора от данни и зависимите променливи.
- Разделете набора от данни на данни за обучение и тест.
- Инициализирайте логистичния модел на регресия.
- Поставете модела с набора от данни за обучение.
- Предскажете модела, използвайки данните от теста и изчислете точността на модела.
Проблем: Първите стъпки са да съберем набора от данни, върху който искаме да приложим Логистична регресия. Наборът от данни, който ще използваме тук, е за набор от данни за прием на MS. Този набор от данни има четири променливи и от които три са независими променливи (GRE, GPA, work_experience), а една е зависима променлива (допусната). Този набор от данни ще покаже дали кандидатът ще получи прием или не в престижен университет въз основа на техния GPA, GRE или work_experience.
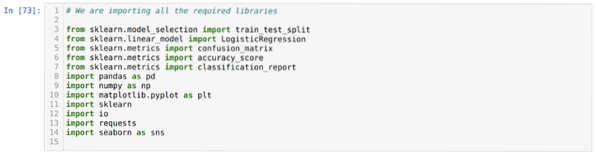
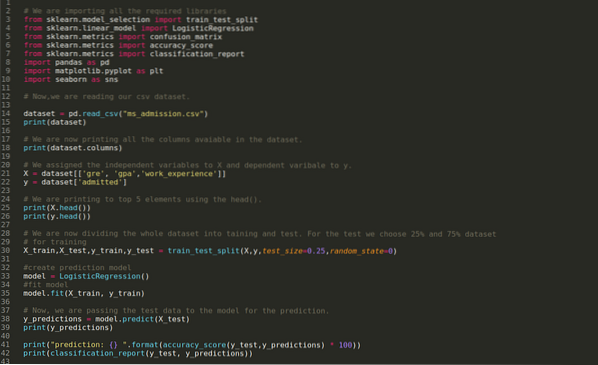
Етап 1: Импортираме всички необходими библиотеки, необходими за програмата python.
Стъпка 2: Сега зареждаме нашия набор от данни за приемане на ms, използвайки функцията read_csv pandas.

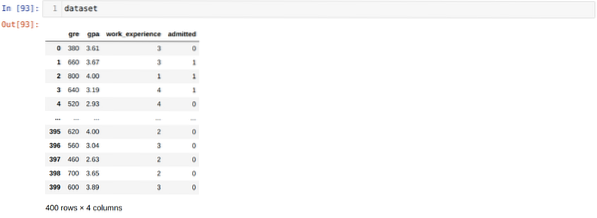
Стъпка 3: Наборът от данни изглежда по-долу:
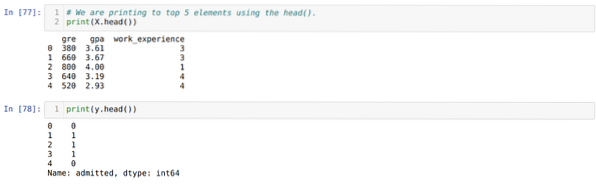
Стъпка 4: Проверяваме всички налични колони в набора от данни и след това задаваме всички независими променливи на променлива X и зависими променливи на y, както е показано на екрана по-долу.

Стъпка 5: След като зададем независимите променливи на X и зависимите променливи на y, сега отпечатваме тук, за да проверим X и y с помощта на функцията head pandas.
Стъпка 6: Сега ще разделим целия набор от данни на обучение и тест. За целта използваме метода train_test_split на sklearn. Дадохме 25% от целия набор от данни на теста, а останалите 75% от набора от данни - на обучението.
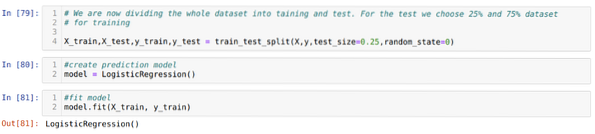
Стъпка 7: Сега ще разделим целия набор от данни на обучение и тест. За целта използваме метода train_test_split на sklearn. Дадохме 25% от целия набор от данни на теста, а останалите 75% от набора от данни - на обучението.
След това създаваме модела на логистична регресия и събираме данните за обучение.
Стъпка 8: Сега нашият модел е готов за прогнозиране, така че сега предаваме данните от теста (X_test) на модела и получихме резултатите. Резултатите показват (y_predictions), че стойности 1 (допуснати) и 0 (неприети).

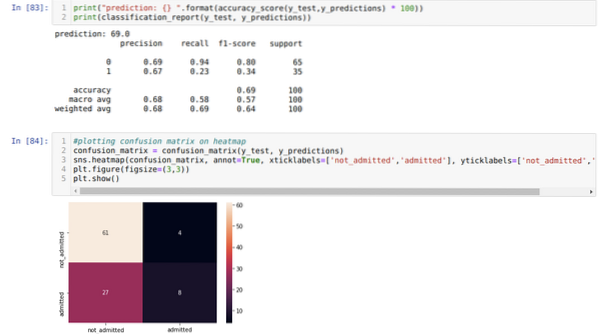
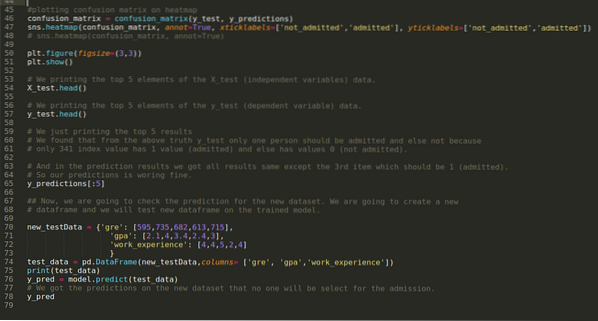
Стъпка 9: Сега отпечатваме доклада за класификация и матрицата за объркване.
Докладът за класификация показва, че моделът може да предскаже резултатите с точност от 69%.
Матрицата за объркване показва общите подробности за данните X_test като:
TP = истински положителни стойности = 8
TN = Истински отрицателни = 61
FP = фалшиви положителни резултати = 4
FN = Фалшиви отрицания = 27
И така, общата точност според confusion_matrix е:
Точност = (TP + TN) / Общо = (8 + 61) / 100 = 0.69
Стъпка 10: Сега ще проверим резултата чрез печат. И така, ние просто отпечатваме първите 5 елемента на X_test и y_test (действителна истинска стойност), използвайки функцията head pandas. След това отпечатваме и първите 5 резултата от прогнозите, както е показано по-долу:
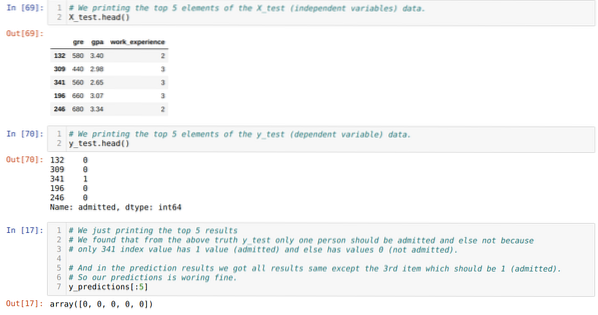
Ние комбинираме и трите резултата в лист, за да разберем прогнозите, както е показано по-долу. Можем да видим, че с изключение на 341 X_test данни, които са били true (1), прогнозата е false (0) else. И така, нашите прогнозни модели работят 69%, както вече показахме по-горе.

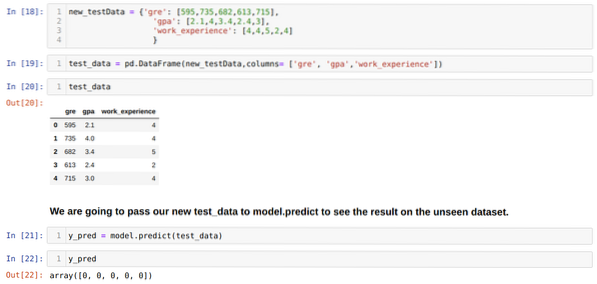
Стъпка 11: И така, ние разбираме как се правят прогнозите на модела върху невидимия набор от данни като X_test. И така, ние създадохме само произволно нов набор от данни, използвайки рамка с данни на pandas, предадохме го на обучения модел и получихме резултата, показан по-долу.
Пълният код в python, даден по-долу:
Кодът за този блог, заедно с набора от данни, е достъпен на следната връзка
https: // github.com / shekharpandey89 / логистична регресия


