Кодът за този блог, заедно с набора от данни, е достъпен на следната връзка https: // github.com / shekharpandey89 / k-значи
Клъстерирането на K-Means е алгоритъм за машинно обучение без надзор. Ако сравним алгоритъма за ненаблюдавано клъстериране на K-Means с контролирания алгоритъм, не е необходимо да обучаваме модела с обозначените данни. Алгоритъмът K-Means се използва за класифициране или групиране на различни обекти въз основа на техните атрибути или характеристики в K брой групи. Тук K е цяло число. K-Means изчислява разстоянието (използвайки формулата за разстояние) и след това намира минималното разстояние между точките от данни и клъстера на центроидите, за да класифицира данните.
Нека разберем K-Means, като използваме малкия пример, използвайки 4-те обекта, и всеки обект има 2 атрибута.
| ObjectsName | Атрибут_Х | Атрибут_Y |
|---|---|---|
| М1 | 1 | 1 |
| М2 | 2 | 1 |
| М3 | 4 | 3 |
| М4 | 5 | 4 |
K-средства за решаване на числов пример:
За да разрешим горния цифров проблем чрез K-Means, трябва да следваме следните стъпки:
Алгоритъмът K-Means е много прост. Първо трябва да изберем произволен брой K и след това да изберем центроидите или центъра на клъстерите. За да изберем центроидите, можем да изберем произволен брой обекти за инициализация (зависи от стойността на K).
Основните стъпки на алгоритъма K-Means са както следва:
- Продължава да работи, докато нито един обект не се движи от своите центроиди (стабилен).
- Първо избираме произволно някои центроиди.
- След това определяме разстоянието между всеки обект и центроиди.
- Групиране на обектите въз основа на минималното разстояние.
И така, всеки обект има две точки като X и Y и те представляват в графичното пространство, както следва:
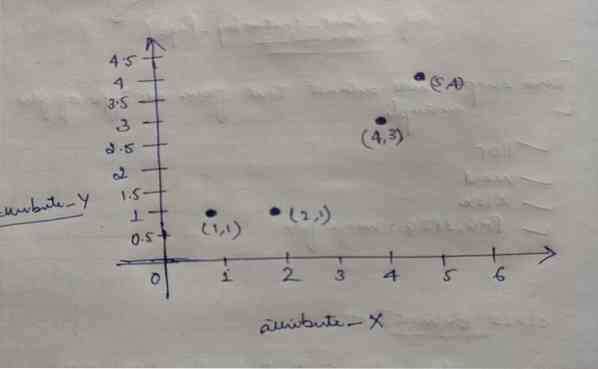
Така че първоначално избираме стойността на K = 2 като произволна, за да решим горния ни проблем.
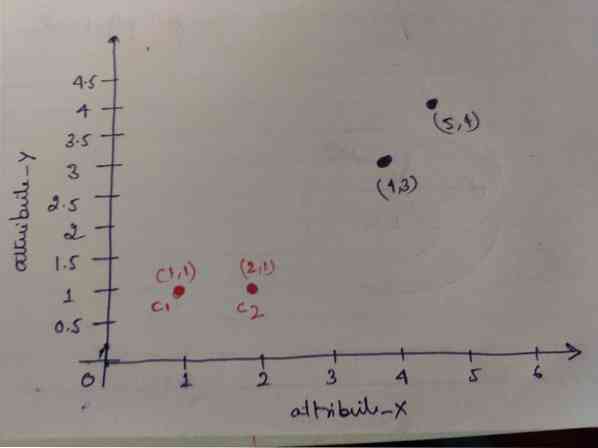
Стъпка 1: Първоначално ние избираме първите два обекта (1, 1) и (2, 1) като наши центроиди. Графиката по-долу показва същото. Ние наричаме тези центроиди C1 (1, 1) и C2 (2,1). Тук можем да кажем, че C1 е група_1 и C2 е група_2.
Стъпка 2: Сега ще изчислим всяка точка от данните на обекта към центроиди, използвайки формулата за евклидово разстояние.
За да изчислим разстоянието, използваме следната формула.

Изчисляваме разстоянието от обекти до центроиди, както е показано на изображението по-долу.

И така, ние изчислихме всяко разстояние от точката на данните на обекта чрез горния метод за разстояние, накрая получихме матрицата на разстоянието, както е дадено по-долу:
DM_0 =
| 0 | 1 | 3.61 | 5 | C1 = (1,1) клъстер1 | група_1 |
| 1 | 0 | 2.83 | 4.24 | C2 = (2,1) клъстер2 | група_2 |
| A | Б | ° С | д | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | х |
| 1 | 1 | 3 | 4 | Y |
Сега изчислихме стойността на разстоянието на всеки обект за всеки центроид. Например обектните точки (1,1) имат стойност на разстояние до c1 е 0 и c2 е 1.
Тъй като от горната матрица на разстоянието откриваме, че обектът (1, 1) има разстояние до клъстер1 (c1) е 0 и до клъстер2 (c2) е 1. Така че обектът е близо до самия клъстер1.
По същия начин, ако проверим обекта (4, 3), разстоянието до клъстер1 е 3.61 и към клъстер2 е 2.83. И така, обектът (4, 3) ще се премести към клъстер2.
По същия начин, ако проверите за обекта (2, 1), разстоянието до клъстер1 е 1, а до клъстер2 е 0. И така, този обект ще премине към клъстер2.
Сега, според стойността на тяхното разстояние, групираме точките (обединяване на обекти).
G_0 =
| A | Б | ° С | д | |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | група_1 |
| 0 | 1 | 1 | 1 | група_2 |
Сега, според стойността на разстоянието, групираме точките (обединяване на обекти).
И накрая, графиката ще изглежда по-долу след извършване на клъстерирането (G_0).
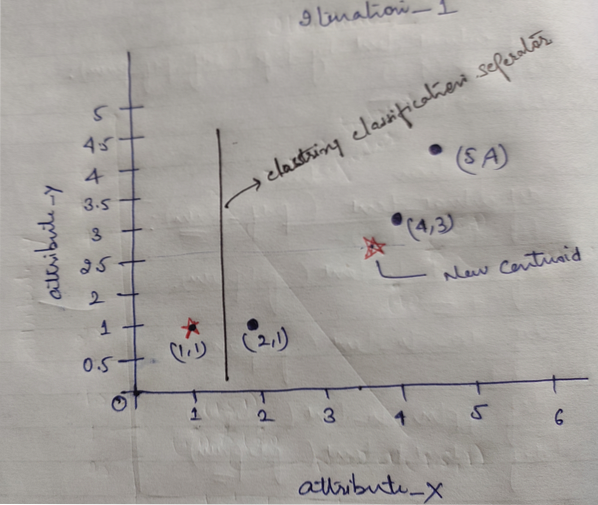
Итерация_1: Сега ще изчислим нови центроиди при промяна на първоначалните групи поради формулата на разстоянието, както е показано в G_0. И така, group_1 има само един обект, така че стойността му все още е c1 (1,1), но group_2 има 3 обекта, така че новата му центроидна стойност е 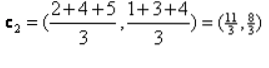
И така, нови c1 (1,1) и c2 (3.66, 2.66)
Сега отново трябва да изчислим цялото разстояние до новите центроиди, както сме изчислявали преди.
DM_1 =
| 0 | 1 | 3.61 | 5 | C1 = (1,1) клъстер1 | група_1 |
| 3.14 | 2.36 | 0.47 | 1.89 | C2 = (3.66,2.66) клъстер2 | група_2 |
| A | Б | ° С | д | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | х |
| 1 | 1 | 3 | 4 | Y |
Итерация_1 (обединяване на обекти): Сега, от името на изчислението на новата матрица на разстоянието (DM_1), ние го групираме според това. И така, преместваме обекта М2 от група_2 в група_1 като правило за минимално разстояние до центроиди, а останалата част от обекта ще бъде същата. Така че новото групиране ще бъде както по-долу.
G_1 =
| A | Б | ° С | д | |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | група_1 |
| 0 | 0 | 1 | 1 | група_2 |
Сега трябва отново да изчислим новите центроиди, тъй като и двата обекта имат две стойности.
Така че, ще бъдат нови центроиди 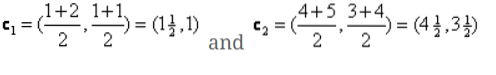
И така, след като получим новите центроиди, групирането ще изглежда по-долу:
c1 = (1.5, 1)
c2 = (4.5, 3.5)
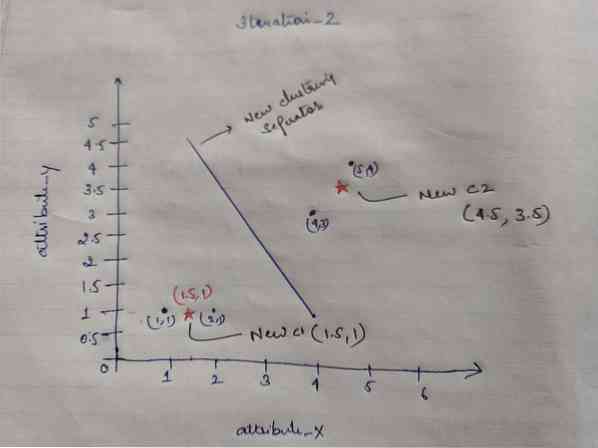
Итерация_2: Повтаряме стъпката, където изчисляваме новото разстояние на всеки обект до нови изчислени центроиди. И така, след изчислението ще получим следната матрица за разстояние за итерация_2.
DM_2 =
| 0.5 | 0.5 | 3.20 | 4.61 | C1 = (1.5, 1) клъстер1 | група_1 |
| 4.30 | 3.54 | 0.71 | 0.71 | C2 = (4.5, 3.5) клъстер2 | група_2 |
A B C D
| A | Б | ° С | д | |
|---|---|---|---|---|
| 1 | 2 | 4 | 5 | х |
| 1 | 1 | 3 | 4 | Y |
Отново правим задачите за клъстериране въз основа на минималното разстояние, както направихме преди. Така че след като направихме това, получихме клъстерната матрица, която е същата като G_1.
G_2 =
| A | Б | ° С | д | |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | група_1 |
| 0 | 0 | 1 | 1 | група_2 |
Както тук, G_2 == G_1, така че не е необходима допълнителна итерация и можем да спрем до тук.
K-Means Внедряване с помощта на Python:
Сега ще приложим алгоритъма K-средства в python. За да приложим K-средствата, ще използваме известния набор от данни на Iris, който е с отворен код. Този набор от данни има три различни класа. Този набор от данни има основно четири функции: Дължина на сепала, ширина на чаша, дължина на венчелистче и ширина на венчелистчетата. Последната колона ще казва името на класа на този ред като setosa.
Наборът от данни изглежда по-долу:
За изпълнението на python k-means трябва да импортираме необходимите библиотеки. Така че ние внасяме Pandas, Numpy, Matplotlib, а също и KMeans от sklearn.Clutser, както е дадено по-долу:

Ние четем Ириса.csv набор от данни, използвайки метода на пандата read_csv и ще покаже първите 10 резултата, използвайки метода на главата.
Сега четем само онези характеристики на набора от данни, които ни бяха необходими, за да обучим модела. И така четем всичките четири характеристики на наборите от данни (дължина на седалката, ширина на седалката, дължина на венчелистчетата, ширина на венчелистчетата). За това предадохме четирите стойности на индекса [0, 1, 2, 3] във функцията iloc на рамката за данни на panda (df), както е показано по-долу:
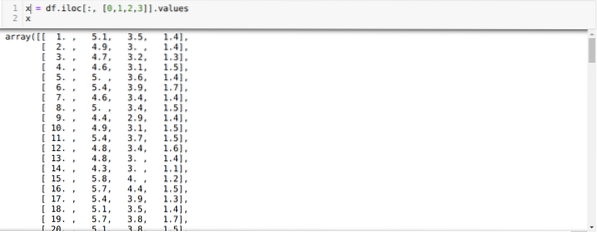
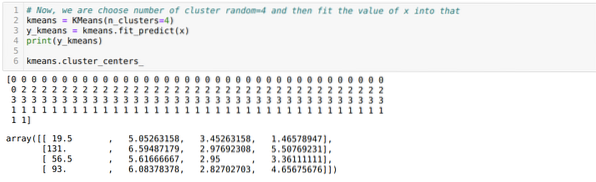
Сега избираме броя на клъстерите на случаен принцип (K = 5). Създаваме обекта от класа K-means и след това събираме нашия набор от данни x в този за обучение и прогнозиране, както е показано по-долу:
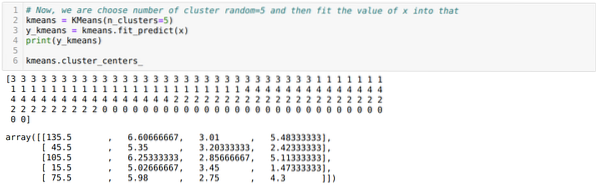
Сега ще визуализираме нашия модел със случайната стойност K = 5. Ясно виждаме пет клъстера, но изглежда, че не е точно, както е показано по-долу.
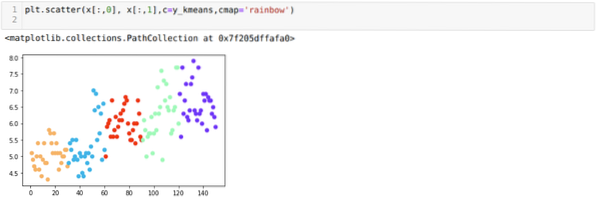
И така, следващата ни стъпка е да разберем дали броят на клъстерите е бил точен или не. И за това използваме метода Elbow. Методът Elbow се използва за откриване на оптималния брой на клъстера за определен набор от данни. Този метод ще се използва, за да се установи дали стойността на k = 5 е била правилна или не, тъй като не получаваме ясна клъстеризация. След това преминаваме към следната графика, която показва, че стойността на K = 5 не е правилна, защото оптималната стойност пада между 3 или 4.
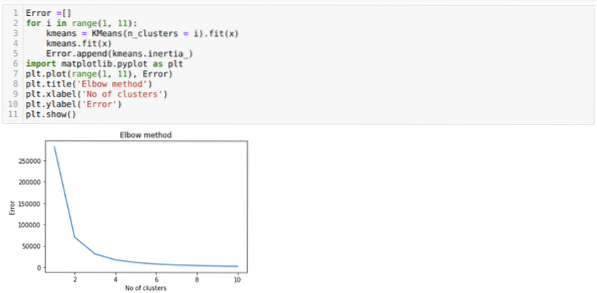
Сега ще стартираме горния код отново с броя на клъстерите K = 4, както е показано по-долу:
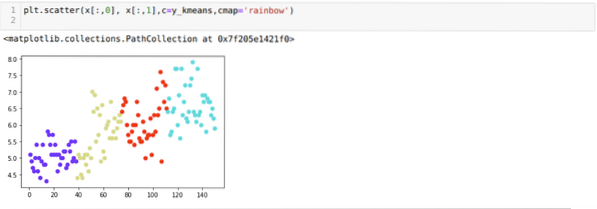
Сега ще визуализираме горното K = 4 ново изграждане на клъстери. Екранът по-долу показва, че сега клъстерирането се извършва чрез k-средата.
Заключение
И така, изучихме алгоритъма на K-средствата както в числов, така и в питонен код. Също така видяхме как можем да открием броя на клъстерите за определен набор от данни. Понякога методът Elbow не може да даде точния брой клъстери, така че в този случай има няколко метода, които можем да изберем.


